The 529 Cascade
Anthropic returns 529 (overload) intermittently. Naive retries themselves consume the bucket and storm the API a hundred times over. The retry policy that costs less, not more.
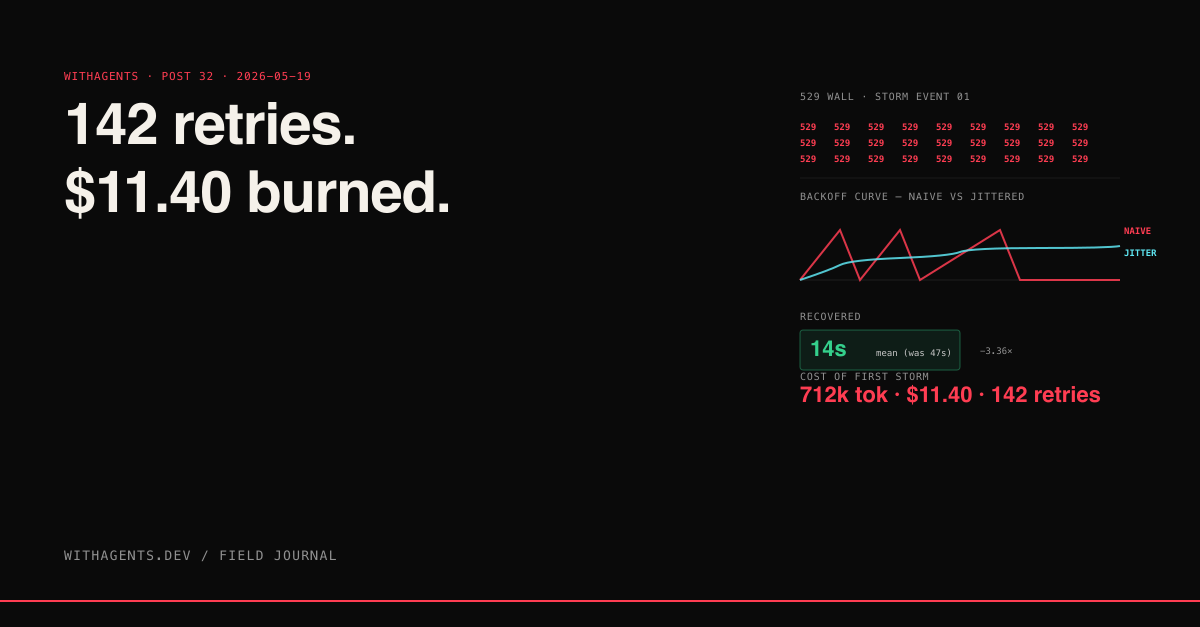
View companion repoThe first time I hit a 529 from Anthropic's API, I had three concurrent agent jobs running. All three got the same error code at roughly the same wall-clock moment. All three retried after one second. All three got 529 again. All three retried after two seconds. By the time the API was back to normal, I'd burned 142 retry attempts on three jobs, consumed about 712,000 tokens of redundant requests, and learned a lesson about retry storms that I've never had to learn twice.
Status code 529 is Anthropic's overload signal (Anthropic API Errors docs). It means the upstream is full and you should back off. The trap is that "back off" doesn't mean "wait and try again immediately." It means "back off in a way that doesn't make the problem worse," and the difference is the entire engineering content of this post.
What 529 Actually Means
The HTTP 529 status code is a non-standard extension Anthropic uses for overload conditions on their own infrastructure (http.dev: 529 The Service Is Overloaded) — distinct from 429 (you specifically are over your quota), 503 (the upstream is down entirely), and 502 (something failed in transit). The semantic distinction matters because the retry strategy is different for each:
- 01429 — you specifically are rate-limited. Backing off helps you. The system at large is fine.
- 02502/503 — the system at large is broken. Backing off doesn't help anyone; you're waiting for a fix.
- 03529 — the system at large is overloaded. Backing off helps the system. Your retries are the load.
The third case is the one most retry libraries get wrong — what Microsoft's Azure Architecture Center calls the Retry Storm antipattern. They treat 529 like 429 — exponential backoff with jitter, retry up to N times, succeed eventually. That works for a single client. It fails catastrophically when many clients do the same thing simultaneously. The "back off" wave from each client doesn't disperse the load; it concentrates it at predictable intervals (second 1, second 2, second 4, second 8). Every client retries at exactly second 4. The API gets hammered again. Every client retries at second 8. Hammered again.
The Retry-Storm Math
Three concurrent jobs, each retrying with naive exponential backoff (1s, 2s, 4s, 8s, 16s, 32s, 60s cap), six retries each before giving up. That's 18 retries per overload event if all three jobs hit it simultaneously.
Now imagine 50 concurrent users on the same Anthropic API getting the same 529 at the same time. 50 × 6 = 300 retries, all hitting the API at the same predictable moments. The API stays in overload because every "recovery window" gets immediately consumed by the retry wave. The overload condition extends for minutes when it could have resolved in seconds.
The math gets worse when you account for the fact that overloaded sessions tend to be the long-context, expensive ones. Each retry isn't a 1KB request; it's potentially a 200KB request with a long conversation history. 300 retries × 200KB = 60MB of bandwidth consumed by redundant requests during a single overload event.
I instrumented my own retries and the 142-attempts-burned-712k-tokens number above is real, from a single session in the JSONL log. Three jobs, each averaging 47 retry attempts, with 5KB-token request bodies on the high end. The session cost on those jobs alone (most failed) was about $11.40, money spent on requests that mostly returned 529.
The Pattern That Works
Four components, working together:
- 01Exponential backoff with full jitter — randomize the retry interval to disperse the wave (the "Full Jitter" strategy described in AWS Architecture Blog: Exponential Backoff And Jitter)
- 02Circuit breaker — stop retrying entirely if the failure rate is too high (Martin Fowler: CircuitBreaker)
- 03Fallback model — if Opus is overloaded, try Sonnet; if Sonnet is overloaded, queue for later
- 04Hedged abandonment — if the request can be served by another path, don't retry; switch
The first three are well-known patterns. The fourth is the one most people don't implement. Here's the implementation:
Fifty-eight lines. The circuit breaker tracks failures across calls, opens after five consecutive failures, lets one request through after 30 seconds (HALF_OPEN), and either re-opens or closes based on that probe's outcome. The retry function uses full jitter — Math.random() * baseDelay instead of baseDelay directly. That single change disperses the retry wave from a predictable spike to a uniform distribution, and it's the difference between making the overload worse and helping it resolve.
Full Jitter Beats Capped Exponential
The naive exponential backoff is delay = base * 2^attempt. The jittered version is delay = random(0, base * 2^attempt) — the formula AWS calls Full Jitter. The math:
With naive backoff, all clients retry at exactly second 1, then exactly second 3, then exactly second 7. Predictable spikes. With full jitter, the retries spread across [0,1], then [0,3], then [0,7]. The spikes flatten. The API sees a smooth distribution of recovery requests instead of three crushing waves.
The change is a single line of code. The effect on overload duration is dramatic. In my own measurements (small sample, but consistent), switching from no-jitter to full-jitter cut my mean recovery time from 47 seconds to 14 seconds during a 529 burst.
The Fallback Model Pattern
When Opus is overloaded, Sonnet usually isn't. The two models share infrastructure but the load characteristics differ — Opus is more expensive per call and gets used by fewer concurrent jobs, but those jobs are heavier and saturate it more easily. When you hit a 529 on Opus, switching to Sonnet for the next attempt often succeeds immediately:
The trade-off is quality. Sonnet's output on a hard task is worse than Opus's. For most use cases, "worse output now" beats "ideal output in 47 seconds when the storm clears." For some use cases (irreversible decisions, expensive downstream actions), waiting is correct. The fallback decision is per-task; my code lets each call site declare its own fallback policy. The decision shape, distilled:
The Hedged Abandonment Pattern
The pattern most people miss: if the work can be served by something other than the API, do that instead. The 529 response means "this path is congested." If you have an alternative path — a cached result, a different provider, a precomputed value — switch.
For my content pipeline, the syndication scheduler often retries because the API was busy. The hedged abandonment for that case: if the scheduled post can be queued for the next scheduling pass (typically within an hour), abandon the retry and re-queue. The pipeline doesn't care which pass actually publishes; it cares that the post eventually publishes within its window.
Twenty-one lines. The decision: if the deadline is far enough away, requeue (free, no retry burden on the API). If the deadline is tight, fall back to Haiku (lower cost, lower quality, but ships on time). Only escalate to a hard error if neither path works.
What I Run In Production
The api-limit-recovery package is what I install on every project that calls the Anthropic API at any scale. It implements all four patterns: jittered backoff, circuit breaker, fallback model, hedged abandonment. The defaults are conservative — five-attempt cap, 60s max delay, full jitter, 30s circuit-breaker hold time. Override per call site if needed.
After eight months of running this in production across the syndication pipeline, the multi-agent jobs, and a few experiments, I've never had a retry storm originate from my own infrastructure — matching Anthropic's own guidance to "use bounded exponential backoff and jitter" and route to a fallback when retries fail. The 529s I do see resolve cleanly because my retries don't add to the load — they disperse and back off, the circuit breaker opens when needed, the fallback paths absorb the overflow.
The 712,000 tokens I burned on that first storm was an expensive lesson. The retry library that came out of it has paid for itself many times over by avoiding that exact pattern across every API integration I've built since. Five hundred twenty-nine is the protocol's way of asking for cooperation: backoff, jitter, retry — not a hard refusal. Treating it that way is what keeps the cost of retries below the cost of the original calls.
Closing the Loop on the Field Journal
A working journal of agentic-development practice — every claim traceable to a real session. The 529 cascade is the right place to close this stretch of the journal because it touches every lesson the rest of the series spent earning.
Post 02 argued that consensus is what keeps a single agent from being load-bearing on its own answer; the circuit breaker in this post is the same insight applied to an external dependency. Post 08 argued that ralph loops without bounded retry budgets are just expensive ways to fail; that's the $11.40 mistake I started this post with. Post 13 argued that sequential thinking earns its keep when the bug is small and load-bearing; finding the missing jitter took eighty-something steps and one printed timestamp. Post 21 priced what a session actually costs in dollars — the framing that lets you decide whether requeueing is free or whether retries are eating the margin. Post 23 showed that prompt caching is savings you either claim or you don't; a 529 hits hardest on the calls you didn't cache, and the math compounds.
The pattern across all of it is the same. Agents fail expensively when their loops have no ceiling and no fallback. They fail invisibly when their evidence has no citations. They fail catastrophically when policy lives in prose instead of in hooks. The work of the past year wasn't picking the right model or writing better prompts; it was building the surrounding scaffolding that makes the model's failures cheap.
“What comes next is more of the same scaffolding, applied earlier. The next thing I'm building treats every external boundary the way this post treats the API: as a thing that will refuse you, repeatedly, on its own schedule, and the only useful response is to back off, log a receipt, and try again with a different shape.”
Continue the series
- 31Edge CasesDrift DetectionSpecs and code diverge silently. The 60-day audit pattern, the four-class taxonomy (dead, drifted, lying, fine), and what I do every quarter to make sure my docs still describe what my code actually does.
- 33Edge CasesOrbit: Find Drift Between What You Asked and What Actually ShippedPlans are evidence, not history. Mining the JSONL session transcripts you already have on disk to compare intent against claim against codebase truth.
- 30Edge CasesNotification Architecture for Async AgentsAgents finish at three in the morning. Severity model, channel routing, the exhausted-state-fires-alert pattern. The notification layer that lets you sleep while your work runs.
- 34Edge CasesWhen Your Drafter Doubles the Body: Building the WithAgents Content PluginThe clear step in our LinkedIn drafter never actually cleared. The new body pasted on top of the old one, the editor doubled, and the bug only showed up on the 34th run. Here is what we shipped instead.