Spec-Driven Development: Why YAML Beats Verbal Instructions for AI Agents
A single YAML file replaces meetings, tickets, and Slack threads — agents read it, build in parallel, and ship without asking clarifying questions
View companion repoFor the first three months, I gave agents instructions the same way I’d talk to a junior engineer. Natural language. “Build me an API that handles user sessions.” “Add a message router that queues when paused.” Conversational. Contextual. Human.
It was a disaster.
Agent 3 would ask “what format does the user object use?” and Agent 5 would answer differently than Agent 1 had already built. Without a shared contract, agents coordinated through hope. Across 23,479 sessions, I can tell you: hope is not a coordination protocol.
The fix was embarrassingly obvious. Stop talking to agents. Start writing specs.
Natural Language Breaks Down Fast
Here’s the failure mode I hit over and over. I’d spin up three agents in parallel:
- 01Agent A: “Build a session manager that creates and tracks user sessions”
- 02Agent B: “Build a message router that sends messages to active sessions”
- 03Agent C: “Build a dashboard that displays session status”
Each agent produced working code. Each agent’s code was internally consistent. The three codebases were completely incompatible. Agent A returns sessions as dictionaries with a state field. Agent B expects session objects with a status enum. Agent C renders a session.is_active boolean that neither A nor B provides.
Natural language is ambiguous. Each agent resolves ambiguity on its own. Tell a human “build a session manager” and they ask clarifying questions. Tell an agent the same thing and it makes assumptions. Three agents, three assumptions, three incompatible implementations.
The numbers back this up. 2,182 TaskCreate calls and 4,852 TaskUpdate calls across my sessions. That 2.2x ratio means every task gets updated more than twice on average. Most of those updates are corrections: “actually, I meant this format.” 111 ExitPlanMode calls confirm planning is a distinct phase agents don’t skip when forced through it.
So how do you kill the ambiguity before agents start building?
YAML as Executable Contract
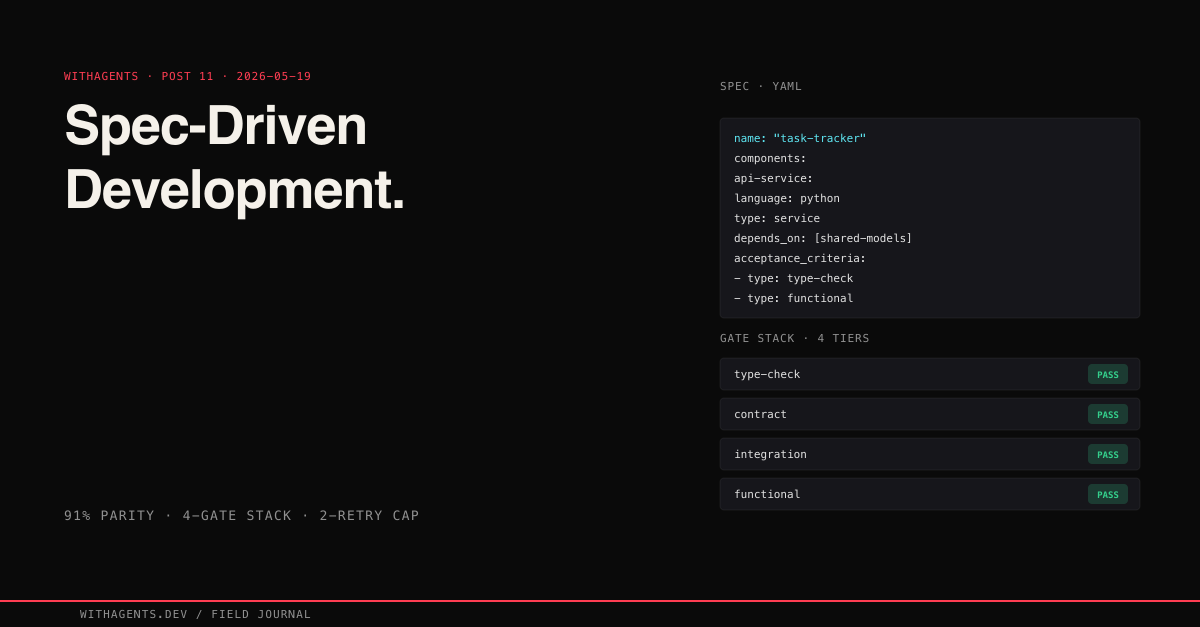
Here’s a YAML spec. Not documentation. Not a README. A contract agents read and build from — every component, every interface, every dependency, every acceptance criterion in one machine-readable file.
From the RepoNexus companion repo, a task-tracker application defined in 60 lines:
The agent building api-service doesn’t ask. The spec says api-service depends on shared-models. The spec says shared-models exports a Python Task model that serializes via to_dict(). That’s the contract. Code against it.
“Specs written for human readability are too vague for agents. Specs written as machine contracts are still perfectly readable by humans.”
Here’s what I learned the hard way: specs written for human readability are too vague for agents. But specs written as machine contracts? Still perfectly readable by humans. And agents can execute against them without guessing.
The RepoNexus Framework
RepoNexus is the framework I built to make this repeatable. Five components, each under 200 lines, each doing one thing.
SpecParser loads YAML files and validates them against a JSON Schema with Draft7Validator. The schema enforces structure: every component declares a language (python, typescript, swift, rust, go) and a type (library, service, cli, app, worker). Acceptance criteria are one of four types: type-check, contract, integration, or functional. If your spec is malformed, parsing fails before any agent starts building.
The parser also validates dependency references. If component api-service declares depends_on: [shared-models] but no component named shared-models exists in the spec, parsing fails immediately. No agent will ever start building against a phantom dependency.
DependencyGraph uses Kahn’s algorithm (topological sort) to figure out build order and catch circular dependencies. But the real value is parallel_layers(), which groups components into layers that can build simultaneously:
In a real application with 8-12 components, layers 0 and 1 might contain 3-4 components each. Those 3-4 agents run in parallel. The sequential bottleneck is the depth of the dependency chain, not the total number of components. You’re parallelizing the build across dependency layers automatically, without any explicit coordination between agents.
AgentScheduler assigns agents to components and runs them layer by layer with bounded parallelism. Failed dependencies cascade. If shared-models fails, api-service and web-frontend get skipped automatically with a clear error message rather than burning compute on code that can’t work.
GateEvaluator runs acceptance criteria as subprocess commands and produces evidence-based reports. Each gate result includes the command output, not just a pass/fail boolean. When a functional gate fails, you see the curl response body or the error traceback. Not a mysterious red X.
PhaseRunner is the GSD pipeline engine: five phases with entry checks, exit gates, and bounded retries. But I need to explain what GSD actually is first.
The GSD Framework
GSD stands for Get Stuff Done. It’s a five-phase state machine that wraps the multi-agent builder into a structured execution pipeline. Each phase has entry conditions, work to perform, exit gates, and (for Verify) rollback triggers.
Discover maps the existing codebase and identifies components. For greenfield projects, this is trivial. For brownfield projects (and let’s be honest, most real projects are brownfield) the Discover phase detects existing code, planning artifacts, and git state before generating anything. What already exists? What does the spec need to account for?
Plan parses the YAML spec, resolves the dependency graph, and validates that all contracts are consistent. This is where SpecParser and DependencyGraph do their work. The exit gate requires a valid build order. If the dependency graph has cycles, planning fails and execution never starts.
Execute spawns agents according to the dependency layers. Layer 0 components (no dependencies) launch immediately. Layer 1 components launch when layer 0 completes. Each agent gets the full spec as context but owns only its assigned component. Agents commit to worktree branches, each one working in isolation with zero file conflicts.
Verify runs every acceptance criterion for every component. The gate hierarchy matters: type-check gates run first (cheapest), then contract gates, then integration gates, then functional gates (most expensive). If type-checking fails, there’s no point running functional validation. Why waste those cycles?
Ship merges worktree branches in dependency order and runs a final global validation pass.
The Verify → Execute rollback is where GSD earns its keep. When verification fails, the framework doesn’t restart from scratch. It identifies which specific components failed their acceptance criteria, spawns agents only for those components, and re-verifies. The retry loop is bounded: two retries max per phase. Three consecutive failures and the framework reports the failure rather than looping forever.
Here’s how PhaseRunner handles that bounded retry logic:
No infinite loops. No “try again until it works.” Bounded retries with evidence at every step.
Why YAML Wins
I’ve tried every format. Markdown specs. JSON schemas. Natural language with structured headers. Plain English with numbered requirements. After running specs through thousands of agent sessions, YAML wins because it forces unambiguous structure (one interpretation per field, no status-as-boolean surprises), it diffs and versions cleanly under git review, and components from one spec become library references in the next so institutional knowledge actually transfers between projects. Concretely:
One interpretation. The field is called status. It’s an enum. The valid values are active, paused, and complete. No agent will implement this as a boolean. When the spec changes, git diff shows exactly what changed: “Added queued to the status enum.” “Changed api-service dependency from shared-models to shared-models, auth-service.” You review spec changes in a pull request the same way you review code changes. The type-check → contract → integration → functional gate hierarchy emerged from the ILS project and I’ve copy-pasted it into every spec since.
The Four Gate Types
RepoNexus defines four types of acceptance criteria, ordered from cheapest to most expensive:
Type-check gates answer one question: does it compile? mypy src/ for Python. tsc --noEmit for TypeScript. swift build for Swift. If your code doesn’t pass static analysis, nothing else matters. These gates run in seconds.
Contract gates answer a different question: does the API match the spec? Serialization round-trips. Schema validation. If the spec says Task.to_dict() returns a dictionary with a title key, the contract gate verifies that claim. These catch interface mismatches before integration, which is the exact failure mode that natural language instructions produce.
Integration gates check wiring: do connected components talk to each other? Health checks. API calls between services. Database connection verification. These require running services, so they cost more than contract gates but catch real plumbing issues.
Functional gates answer the question that actually matters: does it work end-to-end? Can a user create a task through the web frontend, have it stored via the API, and see it persisted? These are the most expensive gates and the only ones users care about. Everything else is a prerequisite.
The GateEvaluator runs them in severity order:
Higher severity means harder to pass and more expensive to run. The evaluator runs all gates and produces an EvaluationReport with pass/fail counts, duration, and the actual command output for failed gates. Not “gate failed.” Instead: “gate failed because curl -sf http://localhost:8000/health returned HTTP 503 with body {"error": "database connection refused"}.”
“Evidence, not assertions.”
The Full Rebuild Test
Here’s the ultimate validation of spec-driven development: take a production app, write the spec from scratch without looking at the existing codebase, feed it to the builder, and compare the output to the original.
I did this with the ILS iOS app. Forty-seven screens, 12 data models, 8 API integrations. I wrote the spec purely from product requirements, based on what the app should do, not how the current code does it. Fed it to the multi-agent builder.
First-pass result: 91% feature parity.
The 9% gap wasn’t bugs. It was undocumented behavior. A retry dialog that pops up after exactly 3 failed attempts, but that rule lives nowhere in any product document. A loading spinner with a different animation on iPad because a designer made that call in a Figma comment. A date formatter that handles Korean locale differently because a user filed a bug six months ago and someone fixed it without updating any spec.
I honestly don’t know how you’d capture all of that in advance. Some of it is institutional knowledge that lives in people’s heads. Maybe there’s a way to mine it out of git history, but I haven’t cracked that yet.
But here’s what the rebuild test does really well: it reveals everything your documentation is missing. If the behavior isn’t in the spec, the rebuild won’t produce it. That forces a decision. Was this behavior important enough to document, or was it accidental complexity that shouldn’t be reproduced?
Every undocumented behavior I found went into the spec. The spec got more precise. The next rebuild got closer to parity. This is the compound effect: each project’s spec captures lessons the previous spec missed.
Specs as Coordination Protocol
The spec replaces meetings, tickets, and Slack threads. Eight agents don’t need a standup. They need a schema.
The time savings come from eliminating coordination overhead, not from faster coding. Agents aren’t writing code faster than I would. They’re writing code without waiting for my context switches, my Slack responses, my “let me re-read this PR before I can answer your question” delays. The spec removes the need for those conversations entirely.
Here’s the workflow I use now for every multi-agent build:
- 01Write the YAML spec (30-60 minutes of focused human work)
- 02Run reponexus validate spec.yaml to catch structural errors
- 03Run reponexus plan spec.yaml to see the dependency layers
- 04Feed the spec to the GSD pipeline
- 05Review gate evaluation reports
- 06Fix failed components and re-verify
Step 1 is the only step that requires sustained human attention. Steps 2-6 are automated. The human cost of a multi-component build collapsed from days of coordination to an hour of spec writing. That’s it.
The reponexus CLI makes the operational loop tight:
What I Got Wrong
I want to be upfront about what doesn’t work.
Specs can’t capture taste. The 9% gap in the rebuild test was mostly aesthetic and UX decisions. Animation timing. Color choices. The “feel” of a swipe gesture. These are human judgment calls that don’t reduce to YAML fields. I stopped trying to spec them and just handle them in a manual review pass after the automated build.
Overspecification kills velocity. My first specs were 400+ lines for a 3-component app. Every field documented, every error case enumerated, every edge case anticipated. The agents followed the spec faithfully and produced bloated, over-engineered code. I learned to spec the contracts and acceptance criteria, not the implementation details. Tell the agent what “done” looks like, not how to get there. The hard lesson was unlearning my urge to be thorough: spec contracts, not implementations.
Specs drift if you don’t enforce them. A spec is only useful if agents actually read it. In early experiments, agents would read the spec, start building, hit an obstacle, and improvise a solution that broke the contract. The fix: gate evaluation. If the spec says the health check returns 200 and the agent’s code returns 204, the gate fails. The agent fixes it. The spec is the authority, not a suggestion.
Practical Advice
If you’re starting with spec-driven development, here’s what I’d do differently knowing what I know now.
Start with 3 components. Not 12. Not 47. Three components with clear dependencies. shared-models → api-service → web-frontend is the canonical starter. Get the spec-parse-build-verify loop working with three components before scaling up.
Write acceptance criteria as shell commands. Not English descriptions. Not pseudocode. Actual commands that return exit code 0 on success and non-zero on failure. curl -sf http://localhost:8000/health is a better acceptance criterion than “the health endpoint should respond successfully.” The first one is machine-executable. The second requires interpretation.
Use the gate hierarchy. Type-check gates are fast and cheap. Run them first. Don’t waste time on functional validation if the code doesn’t compile. The type-check → contract → integration → functional ordering exists because I spent weeks debugging functional failures that turned out to be type errors three layers down. Weeks. I still get annoyed thinking about it.
Version your specs in git. Treat spec changes like code changes. Review them in pull requests. Diff them. When a build fails, git log spec.yaml tells you what changed and when. This sounds obvious in retrospect but I spent my first month with specs in Notion, which has no meaningful diff or version history. What was I thinking?
The RepoNexus companion repo has the full framework: YAML spec parser with JSON Schema validation, dependency-aware agent scheduler with parallel layers, gate evaluator with evidence-based reports, and the GSD phase runner. Clone it, write a spec for a 3-component app, run reponexus plan, and watch the dependency graph resolve. Then wire up your own agent worker function and let the scheduler run it.
“The spec is the product. Everything else is automation.”
Continue the series
- 10Memory & HooksThe Designer-Less Design Workflow: Stitch MCP and the Death of Figma Handoffs269 AI-generated screens, zero Figma files, and the branding bug that taught me to treat prompts as build artifacts
- 12Memory & HooksTeaching AI to Remember: Cross-Session MemoryA SQLite observation store and MCP memory server that turns 23,479 sessions of amnesia into searchable institutional knowledge
- 13Memory & Hooks84 Thinking Steps to Find a One-Line BugHow structured hypothesis-test-revise chains solve bugs that brute force debugging never will
- 14Memory & Hooks35 Worktrees, 12 Agents, Zero Merge ConflictsParallelism gets agents working at the same time. Choreography is what keeps their work from eating itself alive when they finish.