The Five-Layer Streaming Bridge
Token-by-token Claude streaming on iOS — after four failed architectures
View companion repoI wanted one thing: Claude streaming into a SwiftUI view, token by token. Four failed architectures, a five-layer bridge with ten network hops per token, and 7,985 iOS MCP tool calls later, I had something that actually worked.
Here’s the story. What broke, why it broke, and why the “complicated” solution turned out to be the only simple one.
The Problem Nobody Warns You About
Claude Code has streaming. The terminal shows tokens arriving in real time. The Python SDK streams. The JavaScript SDK streams. So connecting an iOS app should be straightforward, right?
It’s not. Claude Code doesn’t use API keys. It uses an OAuth session token that the CLI manages internally. You can’t import an HTTP client in Swift, hit the Anthropic API, and parse the responses. The authentication boundary is fundamentally different from what iOS developers expect, and that single fact blows up every “obvious” architecture.
I learned this across the ils-ios project: 4,241 files, 1,563,570 lines of code, 128 xcode_build invocations, 2,165 simulator_screenshot calls. The iOS simulator became my second screen. Build, screenshot, tap, verify. Repeat.
Four Architectures That Failed
Each attempt looked reasonable on paper. Each failed for a reason that was invisible until I ran it on a real device.
Attempt 1: Direct API calls from Swift. The obvious first move. Import URLSession, construct the request, hit the Anthropic API endpoint, parse the SSE stream. Swift has excellent async/await support for streaming HTTP responses. Should take an afternoon.
Not a key management problem. Claude Code authenticates through an OAuth session token flow that the Python SDK handles internally. There’s no API key to put in your keychain. The CLI manages a session token that refreshes automatically, and that token exchange isn’t exposed as a public interface. The API isn’t designed for direct client access from a mobile app.
Dead end. The authentication model itself is incompatible.
Attempt 2: JavaScript SDK via Node subprocess. Spawn a Node.js process from Swift using Process(), pipe the official JavaScript SDK’s output back to the app. Node authenticates, Swift reads stdout. Simple IPC.
The subprocess launched. The SDK authenticated. Then silence. No output. No error. Just a hanging process consuming CPU.
The problem: SwiftNIO event loops don’t pump RunLoop. Swift’s networking layer and Node’s event loop are independent scheduling systems. Running both in the same process creates a mismatch where neither yields to the other. The subprocess hung on its first async operation and never recovered. Two correct runtimes that become incorrect when composed.
Attempt 3: Swift ClaudeCodeSDK in Vapor. Use the Swift SDK wrapper inside a Vapor server running on localhost. Two Swift processes, the app and the server, communicating over HTTP. Both are Swift, so the type system aligns. Should be clean.
The ClaudeCodeSDK uses Foundation’s FileHandle for process communication, which requires a RunLoop. Vapor uses SwiftNIO, which provides EventLoop, a fundamentally different concurrency primitive. FileHandle.readabilityHandler callbacks are scheduled on a RunLoop that SwiftNIO never creates. The callbacks register, then never fire. Two Swift frameworks that are individually correct but architecturally incompatible.
Attempt 4: Direct CLI invocation. The simplest approach. Shell out to the claude CLI from Swift and read its stdout stream-json output.
The CLI checks for a CLAUDECODE=1 environment variable at startup. When the iOS app (running inside a Claude Code development session) spawns the CLI, the parent process’s environment propagates to the child, including that flag. The CLI sees the variable and refuses to start, assuming it’s being invoked recursively.
Ambient environment contamination. The parent’s environment poisons the child’s startup check.
The Architecture That Survived
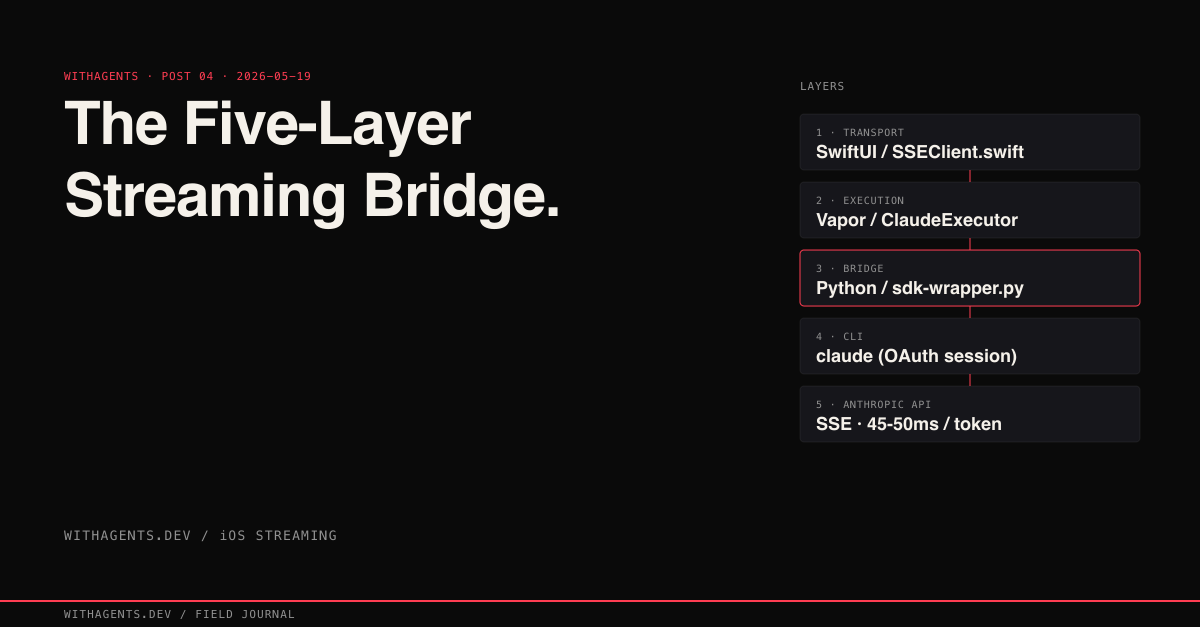
After four failures, a pattern clicked. Each attempt failed at a boundary: authentication, event loop, concurrency model, or environment. The solution was to make each boundary explicit, with a dedicated layer for each translation.
Ten hops per token. The SwiftUI app sends an HTTP POST to the local Vapor server. Vapor’s ClaudeExecutorService actor spawns a Python subprocess. Python invokes the Claude CLI with environment variables stripped. The CLI authenticates via OAuth and calls the Anthropic API. The response travels back through each layer in reverse: API to CLI stdout, CLI to Python stdout, Python to NDJSON line, NDJSON to StreamMessage decode, StreamMessage to SSE event, SSE event to SwiftUI view update.
Five layers. Five files. Each with a single job:
Here’s the Vapor route that opens the SSE connection and proxies tokens from the ClaudeExecutorService to the iOS client:
Three headers matter here. text/event-stream tells the iOS URLSession this is an SSE response, not a buffered download. Cache-Control: no-cache prevents any proxy from buffering events. X-Accel-Buffering: no disables nginx proxy buffering if the Vapor server sits behind a reverse proxy in staging. Miss any one of these and the client either never receives events or receives them in bursts.
Every layer exists because I tried to remove it and the system broke. Remove Python and Swift can’t authenticate against the Anthropic API. Remove the StreamMessage type layer and snake_case JSON from Python crashes the Swift decoder. Each removal trial taught the same lesson: the layer wasn’t decoration, it was a translation step that something downstream depended on.
“More layers meant fewer failure modes. Each layer does exactly one translation. When a bug shows up, it lives in exactly one layer, and the layer boundaries tell you which one.”
The SSE Connection State Machine
The SSEClient manages more state than you’d expect for “just reading an HTTP stream.” Network connections drop. The app backgrounds. The server restarts. Each state transition needs explicit handling, or the user sees a frozen UI with no explanation.
Four states, explicit transitions for every edge case. Two-tier timeouts separate “stuck process” (no output in 60s) from “runaway process” (still running after 5 min). A heartbeat watchdog via OSAllocatedUnfairLock catches silent connection drops without actor-hop overhead on the hot path.
The two-tier timeout strategy is worth walking through. The initial 60-second timeout races the HTTP connection against a Task.sleep. Whichever finishes first wins:
Once connected, a heartbeat watchdog takes over. A LastActivityTracker records the timestamp of every received SSE line using OSAllocatedUnfairLock. Why not an actor? Because actor hops on every SSE line (the hot path during streaming) add measurable latency:
A detached task checks every 15 seconds whether the last activity was more than 45 seconds ago. If so, the connection’s considered stale and reconnection begins with exponential backoff capped at 30 seconds.
There’s an iOS-specific wrinkle too: backgrounding. iOS kills background network connections aggressively. The SSE client registers for UIApplication.didEnterBackgroundNotification and cancels the active stream immediately rather than letting iOS kill it unpredictably. When the app foregrounds, the user can reconnect explicitly. Ever tried to be clever about maintaining background connections on iOS? That’s a path to battery drain complaints and App Store rejection. Don’t do it.
The Bugs That Hide in Streams
Static analysis can’t catch streaming bugs. The types compile. The logic looks correct. The bug only shows up when real tokens flow through the system at real speeds.
Bug 1: Block-Buffered stdout
Python’s subprocess stdout is block-buffered by default, not line-buffered. The Python bridge wrote NDJSON events to stdout, but Python’s runtime held them in a 4KB buffer. The Swift side received nothing for seconds, then a burst of stale tokens all at once.
The user experience was terrible. No text for three seconds, then half a paragraph appearing instantaneously, then silence again. It looked like the connection was broken, then miraculously fixed, then broken again.
The fix was one line in the Python bridge that took hours of debugging to find:
sys.stdout.flush() after every line. Forces the buffer to drain on every newline, which aligns with NDJSON’s line-delimited format. Token latency dropped from seconds to the actual network latency, roughly 50ms per token in steady state.
I almost scrapped the Python bridge entirely and rewrote it in Go before realizing the problem was a single missing function call. I was ready to throw away an entire architecture layer over a buffer flush.
Bug 2: The Text Duplication Trap
This one cost me a full day. The assistant was saying everything twice. “Hello, how can I help you?” rendered as “Hello, how can I help you?Hello, how can I help you?” in the chat view.
The root cause lives in how Claude’s streaming protocol works. Each assistant event contains the accumulated text so far, not a delta. If the model has generated “Hello, how can I” so far, the assistant event’s text field contains the entire string “Hello, how can I”, not just the latest token.
The natural instinct is to append:
The fix is assignment:
But here’s the trap: streamEvent deltas work the opposite way. Each textDelta contains only the new characters since the last delta. For deltas, += is correct:
Two event types, opposite semantics, same data shape. The StreamMessage type system in StreamingTypes.swift makes this explicit by separating .assistant (accumulated) from .streamEvent (incremental) at the enum level, but the developer consuming these types still needs to know the difference. I honestly didn’t expect a streaming protocol to have this kind of split personality, and I’m still not sure it’s the best design choice. But it’s the reality you work with.
Bug 3: Environment Variable Contamination. The fourth failed architecture’s CLAUDECODE=1 problem persisted even in the working five-layer bridge. The Vapor server inherited the parent environment, passed it to the ClaudeExecutorService actor, which passed it to the Python subprocess, which passed it to the CLI. Five layers deep, and the environment variable from the outermost process still poisoned the innermost one.
The ClaudeExecutorService strips Claude-related variables with a belt-and-suspenders approach, both in the shell command and in the Process.environment:
Three lines of environment cleaning in each approach. Without either one, the entire five-layer bridge fails silently on the last hop. No error message. No stderr output. Just a zero-byte response and a confused developer staring at process exit code 1.
This fix took a full session to discover. The symptom, “works in Terminal, fails inside Claude Code,” pointed nowhere useful until I dumped the subprocess environment and saw the contaminating variables.
The Process Lifecycle Trap
Swift’s Process class has a subtle but devastating API design issue that bit me during the streaming bridge work.
When you read from a process’s stdout pipe and reach EOF, your natural assumption is that the process has exited. It hasn’t. There’s a race condition between the pipe closing and the process terminating. If you read process.terminationStatus before the process has actually exited, Foundation throws NSInvalidArgumentException, a runtime crash, not a compiler error.
The fix is ordering:
But there’s a second trap hiding in waitUntilExit(). If the subprocess writes more than 64KB to its stdout pipe before you drain it, the pipe buffer fills. The process blocks waiting for the pipe to drain. Your code blocks on waitUntilExit() waiting for the process to finish. Deadlock. Neither side can proceed.
The correct order is: drain the pipe first, then wait for exit. The ClaudeExecutorService handles this by reading stdout on a dedicated GCD queue (DispatchQueue with .userInitiated QoS) that drains data continuously. The waitUntilExit() call comes after the read loop exits:
This ordering, drain pipe then wait for exit then read status, is the only sequence that avoids both the deadlock and the crash. Miss either constraint and the bridge fails intermittently under load. That’s the worst kind of failure because it passes every check you throw at it during development and only surfaces in production.
The Two-Tier Timeout System
Streaming creates a timeout problem that request-response architectures don’t have. How long is too long to wait?
A deadlocked process produces no output. A legitimate large response produces output continuously for minutes. A single timeout value can’t tell the difference.
The bridge uses two independent timeouts:
Initial timeout (30 seconds): Fires if zero bytes arrive on stdout after process launch. This catches a stuck CLI, whether from authentication failure, environment contamination, or a deadlocked subprocess. If the process can’t produce any output within 30 seconds, something is fundamentally wrong. Kill it.
Total timeout (5 minutes): Fires regardless of output. This catches runaway processes, like a model generating an unexpectedly long response or a subprocess that’s producing output but will never finish. The 5-minute cap is generous enough for legitimate responses but prevents resource exhaustion.
The initial timeout cancels itself on first data received. Both are implemented as DispatchWorkItem instances scheduled on a global queue, which avoids any dependency on RunLoop (critical for Vapor/NIO compatibility):
When the first chunk of stdout data arrives, timeoutWork.cancel() disarms the initial timeout. The total timeout keeps running independently.
Performance: What Ten Hops Actually Cost
Does five layers kill performance? That’s the first question everyone asks.
The cold start is painful. Python interpreter initialization, SDK import, CLI authentication: 12 seconds of startup before the first token appears. But the warm path is fast. Once the bridge is running, the per-token overhead of five layers is under 5 milliseconds. The Anthropic API’s own latency (~45-50ms per token) dominates. The bridge becomes invisible.
Here’s the lesson I keep coming back to: architectural overhead matters at connection time, not at streaming time. Users tolerate a slow initial connection if the subsequent streaming feels instantaneous. The SSEClient shows a “Connecting…” status during cold start and “Taking longer than expected…” after 5 seconds, which sets expectations correctly.
The @Published Infinite Recursion
One war story from production that I think every SwiftUI developer should know about.
The error: Thread stack size exceeded due to excessive recursion. The stack trace showed an infinite loop between two @Published properties. AppState.showOnboarding had a didSet that updated ConnectionManager.showOnboarding, which had a Combine subscription that set AppState.showOnboarding, which triggered didSet again.
The usual fix, “check if the value actually changed before setting,” doesn’t work with @Published. And this is the critical detail that tripped me up: @Published emits on willSet, before the stored value updates. When the emission fires, the stored property still has the old value, so a guard like guard newValue != showOnboarding reads the pre-update value and concludes the value is different. The guard passes. The cycle continues.
The actual fix required removeDuplicates() and dropFirst() on the Combine subscriptions:
removeDuplicates() catches the semantic duplicate. dropFirst() prevents the initial value emission from triggering a set. Both are necessary. Either one alone still allows the cycle under specific timing conditions.
This is why the ChatViewModel in the companion repo uses @Observable with manual withObservationTracking instead of @Published with Combine. The observation tracking pattern gives explicit control over when and how the view model processes changes, with a high-water mark pattern that prevents message replay:
Without this high-water mark, ending a stream resets the processed message index to zero, causing the next observation cycle to replay every message from the beginning and duplicating the entire conversation.
What 7,985 Simulator Interactions Taught Me
The ils-ios project, the native iOS client where this streaming bridge was born, accumulated 7,985 MCP tool calls to the iOS simulator: 2,620 idb_tap actions, 2,165 simulator_screenshot captures, 1,239 idb_describe accessibility tree queries, 479 gestures, 443 element searches. Build, screenshot, tap, verify. Repeated thousands of times across the development cycle.
What does iOS development with AI agents actually look like? It’s not “generate code and ship.” It’s “generate code, build, launch on simulator, screenshot the result, tap through the flow, screenshot again, find the bug in the screenshot, fix the code, build again.” The ratio of verification actions to code-writing actions is roughly 4:1. Four taps and screenshots for every meaningful code change.
The streaming bridge was the foundation that made everything else work. Without reliable token-by-token streaming, the iOS app was just a request-response interface. You’d type a message, wait, then see the complete response. With streaming, users read the first sentence while Claude’s still generating the tenth. Perceived latency dropped from 15 seconds (full response time) to under 1 second (first token time). Same underlying speed. Completely different user experience.
Lessons for Your Own SSE Bridge
If you’re building a streaming bridge for any iOS app, not just for Claude, these are the hard-won patterns:
- 01Flush your stdout. Every language buffers process output by default. Python needs sys.stdout.flush(). Node needs explicit stream flushing. If your stream appears to “batch” events, check buffering before you check your architecture.
- 02Distinguish accumulated from incremental. Your protocol needs to be explicit about whether each event contains the full state or just the delta. Document it. Enforce it in types. The = vs += bug will find you if you don’t.
- 03Strip inherited environment variables. Any subprocess inherits the parent’s environment. If your parent process sets variables that affect child behavior, strip them explicitly. Belt and suspenders: strip in the shell AND in the Process API.
- 04Drain pipes before waiting for exit. Process.waitUntilExit() deadlocks if the child’s stdout buffer is full. Read all data first. Wait for exit second. Read termination status third. This ordering is non-negotiable.
- 05Use two-tier timeouts. A stuck process (no output) and a long process (continuous output) need different timeout strategies. One timeout can’t serve both purposes.
- 06Cancel on background. On iOS, don’t try to maintain SSE connections when the app is backgrounded. Cancel cleanly and reconnect on foreground. The alternative is battery drain and App Store rejection.
- 07Use OSAllocatedUnfairLock on hot paths. Actor hops are safe but slow for per-token operations. Lock-based synchronization is appropriate when you need thread safety without the overhead of actor scheduling on code that runs hundreds of times per second.
The companion repo at github.com/krzemienski/claude-ios-streaming-bridge has the complete Swift Package with SSEClient, ClaudeExecutorService, StreamingTypes, and the Python sdk-wrapper.py bridge. Add it via SPM, point it at your backend, and you’ve got token-by-token streaming from Claude to SwiftUI.
Continue the series
- 03FoundationI Banned Unit Tests and Shipped FasterWhy functional validation replaced testing when AI writes the code
- 02Foundation3 Agents Found the Bug 1 Agent MissedWhy multi-agent consensus catches what solo review cannot
- 01Foundation23,479 Sessions: What Works in Agentic DevWhat 11.6GB of session data across 27 projects reveals about building production software with AI agents
- 05ValidationiOS Patterns from 4,597 Agent SessionsWhat 4,597 sessions taught me about SwiftUI, state, and survival — five patterns from three iOS apps that earned their keep or crashed.