Crucible: Refusal-Driven Verification for Claude Code
The gate between 'I did the work' and 'the work is done' — 10 phases, 3 reviewers, 3 oracles, zero override flags.
View companion repo09:15:29 — Crucible’s /forge dispatched a planner subagent. 09:18:42 — codebase-analysis SUMMARY.md landed at 4,200 words. 09:23:11 — three reviewers (A/B/C) spawned in parallel; each reviewed evidence in its own isolated context. 09:24:38 — decision.md returned the literal substring UNANIMOUS PASS. 09:25:02 — three oracle auditors fanned out. 09:26:14 — quorum: ≥2 APPROVE, zero unresolved blockers. 09:26:45 — gate.py walked the MSC table. 09:26:46 — report.json wrote overall=COMPLETE.
That transcript is real. It’s from the Crucible trial labeled 20260425T091529Z-planning — 52 transcript messages, zero Write or Edit tool uses during the run, Iron Rule HONORED, Outcome PASS. The receipts are at evidence/robust-trials/trial-01/OUTCOME.md in the Crucible repo.
Crucible refuses to let a session end until that gate fires. There is no --force flag. There is no “approve with concerns.” If evidence/completion-gate/report.json doesn’t exist, or it exists but overall != "COMPLETE", the Stop hook returns exit 2 and the session stays open. Refusal is not a bug. It’s the feature.
The Problem
Across 23,479 sessions of Agentic Development, a recurring failure mode kept resurfacing. The agent declared a task complete. The build passed. The lint was clean. Sometimes the unit tests even ran green. And then a week later the feature didn’t work.
The pattern is structural, not adversarial. LLM-driven systems are trained to produce coherent text. Coherent text is not evidence. An agent reviewing its own work has no independence — it’s the same context window that produced the work in the first place. A Done! followed by a closed session is a coherent ending; it is not proof of correctness.
Crucible exists to remove the option of faking completion. It does this at the plugin layer through three moves: hooks watch every tool use, verdicts must cite paths, and the producer is structurally separated from the reviewer.
What Ships
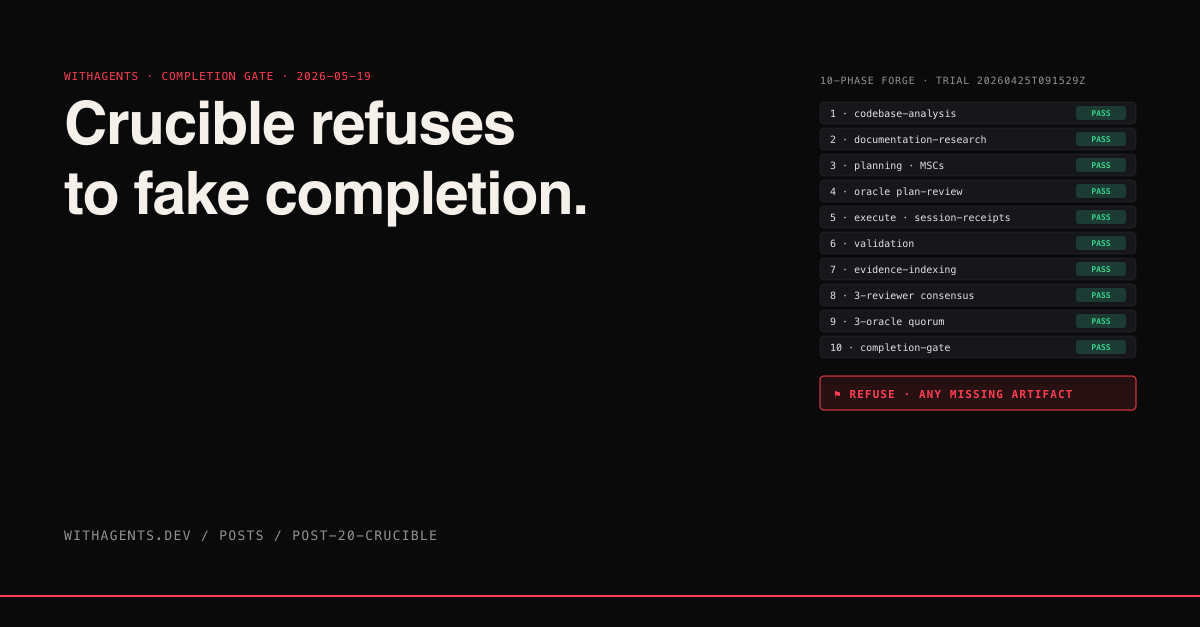
The plugin ships with verbatim counts: 19 slash commands, 10 subagents, 11 skills, 4 hooks, 4 rule templates. Three command tiers — orchestrators, authoring, inspection. The orchestrators are /crucible:forge, /crucible:autopilot, /crucible:remediate, /crucible:resume, and /crucible:trial. Forge is the conductor.
The conductor runs ten phases:
Each phase has a refusal trigger. If phase 1 doesn’t produce a non-empty SUMMARY.md, phase 2 never starts. If phase 4’s oracle returns BLOCK, execution never starts. If the three reviewers in phase 8 don’t unanimously PASS, the oracle quorum is skipped and a REFUSAL.md lands. The pipeline halts at the first refusal. There is no “best effort” advancement.
That last sentence is the structural one. Most validation systems are advisory: they produce a report, the human decides whether to ship. Crucible inverts the default. The session cannot end on its own — the Stop hook checks report.json and returns exit 2 unless overall=COMPLETE. To ship, you have to satisfy the gate. To bypass the gate, you have to explicitly disable Crucible (/crucible:disable or touch .crucible/disabled). There is no middle path.
The Four Iron Rules
The discipline reduces to four rules, installed verbatim into your project’s CLAUDE.md by /crucible:setup:
RL-1 — No mocks. Validation runs against real systems only. The PreToolUse hook rejects writes to *.test.*, *.spec.*, tests/, __tests__/, mocks/, fixtures/, *.fixture.*, *.mock.*. It also rejects bash commands that install or invoke test frameworks (pytest, jest, vitest, mocha). An agent that can’t satisfy a missing-test gap by writing a fake test will, eventually, satisfy it by exercising the real system.
RL-2 — Cite or refuse. Every PASS / FAIL / APPROVE / BLOCK verdict must cite a specific evidence file path. A PASS verdict that lacks a citation is INVALID. This is what makes the evidence package independently auditable: a reviewer who has never seen the agent’s reasoning can read report.json, follow each citation, and reproduce the verdict.
RL-3 — No self-review. The agent that produced an artifact may not also review or approve it. The planner does not review its own plan; the oracle plan-review is a separate subagent invocation. The validator does not approve its own verdict; reviewer consensus is required. Reviewers cannot write each other’s verdicts. Independence is structural, not advisory — each reviewer runs in its own isolated Task context and cannot see the others’ output until the parent synthesizes.
RL-4 — Cite paths (specificity). Citations must be maximally specific. evidence/session-logs/<id>/session.jsonl:42-58 is ideal. evidence/oracle-plan-reviews/<id>/plan.md is acceptable. evidence/ is too broad and refused. The completion-gate parses citations and rejects any that don’t resolve to a real, non-empty file or directory.
These rules feel restrictive until you hit your first refusal. Then they feel like guardrails. Then they feel like the whole point.
A Real Run
The transcript that opens this post is from evidence/robust-trials/trial-01/. The full receipt block:
What that trial proved: when Crucible runs /forge on a task whose plan is a planning-only artifact (i.e., the deliverable is the plan itself, not code), the validator can confirm Iron Rule compliance by parsing the session JSONL and asserting zero Write/Edit tool uses. The audit is line-cited — AUDIT-INDEX.md references each hook firing with the specific JSONL line number. A separate human auditor could re-derive the conclusion without re-running the agent.
Trial-04 ran the same pattern but for SDK-driven validation: the run was dispatched through claude_agent_sdk.Anthropic.messages.create rather than the interactive CLI. The hooks fired identically. The session-receipt JSON tagged the origin as sdk instead of cli. Same Iron Rule. Same evidence shape.
The point is reproducibility. Two trials, two driving paths, identical evidence schema. The discipline doesn’t depend on how the session was started.
Quorum Mechanics
Crucible enforces independence in two places: 3-reviewer consensus (phase 8) and 3-oracle quorum (phase 9).
The reviewers cover orthogonal dimensions:
Decision rule: UNANIMOUS PASS or REFUSED. No majority path. The three dimensions are orthogonal — a 2/3 vote is a real gap, not a swing voter. The synthesizer writes decision.md containing the literal substring UNANIMOUS PASS (the gate searches for that exact string).
The oracles are different:
Decision rule: ≥2 of 3 APPROVE AND zero unresolved critical blockers. A single Oracle’s BLOCK with a cited critical blocker overrides two APPROVEs — because the cited blocker is a real defect, not a vote against quorum.
The two layers measure different things. The reviewers are oriented at the evidence package: does what’s there hold up? The oracles are oriented at the project: does what’s there cover the contract? An incomplete project can have rigorous evidence (reviewers PASS, oracles BLOCK). A complete project can have sloppy evidence (oracles APPROVE, reviewers REFUSE). Both must agree before the gate fires.
Refusal Is Not a Bug
When any phase’s exit criterion is unmet, Crucible writes a structured REFUSAL.md and stops. The schema is mechanical:
A refusal is not a soft warning. It’s a structured, machine-readable diff between the system’s contract and its reality. It’s the fastest path to “actually done” because the gaps are named. You can’t talk Crucible into passing — you can only fix the cited gap and re-run.
/crucible:autopilot runs forge in a refusal-driven retry loop. Each iteration reads the latest REFUSAL.md, asks the planner for a delta plan covering only the failing MSCs, executes it, and re-runs the gate. Default --max-attempts=3. If the loop exits REFUSED, the surviving MSCs are real defects in your task definition, not transient agent failures. Iron Rule preservation across retries is mechanical — every iteration runs through the same hooks, so a retry that tries to write a mock test gets the same exit-2 rejection the first attempt did.
The Lessons That Cost Real Time
I broke Crucible five different ways before it shipped clean. The most expensive lesson:
Verdicts without citations are invisible failures. I had an early build where the planner returned a plan with MSCs that read measurable but had no citation paths. The plan-review oracle approved it. Execution started. Halfway through, the validator returned PASS verdicts that named no evidence files. The completion-gate accepted them — the schema wasn’t strict enough — and the session ended with overall=COMPLETE. But the work wasn’t actually done. The MSCs had been “passed” by claim, not by file. Fix: the gate now refuses any MSC whose citation path doesn’t resolve to a real, non-empty file. RL-2 was a discipline rule before it was an enforced one. After this trial, it became enforced.
Independence has to be structural, not procedural. I tried for a while to enforce no-self-review by adding a rule to the planner’s prompt: “Do not approve your own plan.” It worked some of the time. The structural fix was to make the oracle plan-review a separate subagent invocation in a fresh Task context with no shared memory. Once each reviewer ran in its own isolated context, the rule became unbreakable — not because the prompt said so, but because the subagent literally couldn’t see its own plan output to “remember” what it had written.
The Stop hook is the structural primitive. Without it, completion is a soft notion. The agent says “done” and the session ends. With it, completion is binary: report.json exists and overall=COMPLETE, or the session can’t end. Every other discipline in Crucible feeds into that one check. Removing the Stop hook would turn Crucible into an advisory tool. Keeping it makes Crucible a gate.
How It Composes
Crucible is one of three tools I use to ship agentic features. Each owns a different question:
- 01Anneal (Post 19) answers what’s the plan? It refuses to let a bad plan reach a good agent.
- 02ValidationForge (Post 3) answers does it work? It generates evidence-cited validation runs without mocks.
- 03Crucible (this post) answers is the work done? It refuses to let “done” leave the session without proof.
The three compose. Anneal’s plan can satisfy a Crucible MSC. ValidationForge’s evidence package can be cited in a Crucible verdict. Crucible’s report.json can become a CI artifact that ValidationForge re-validates against. None of them replaces the others. All three together cover plan quality, validation rigor, and completion discipline.
For solo work, I run them in sequence: Anneal writes the plan, Crucible’s /forge executes it, ValidationForge generates the cross-platform evidence. For team work, the three become roles — the planner who runs Anneal, the implementer who runs /forge, the validator who runs ValidationForge against the deliverable. The Iron Rules carry across.
Install and Use
Source, the trial evidence packages, and the rule templates are at github.com/krzemienski/crucible. The product page lives at withagents.dev/products/crucible.
The boulder still has to roll. Crucible’s job is to refuse the "we’re done" verdict until the evidence package backs it up.
Continue the series
- 21OperationsThe Economics of a SessionToken spend per task complexity, when Opus actually pays back over Sonnet, and the cost-of-defect curve that makes "use the cheap model" the most expensive choice you can make
- 22OperationsHooks as a Control PlaneFour hook events form the entire governance surface of Claude Code — refuse tools, gate commits, block deploys, enforce evidence. Once you see it as a control plane, the whole agent stack changes shape.
- 23OperationsPrompt Caching EconomicsCache reads cost a tenth what cache writes cost, and most agents leave that 90% discount on the table because nobody structures their system prompt for hits. Here's how to order your messages so the cache pays you back.
- 24OperationsCustom MCP ServersWhen the prebuilt MCP servers run out of road, you write your own. The protocol is a four-method handshake, the transport is stdio or HTTP, and the whole thing fits in 200 lines of TypeScript.