23,479 Sessions: What Works in Agentic Dev
What 11.6GB of session data across 27 projects reveals about building production software with AI agents
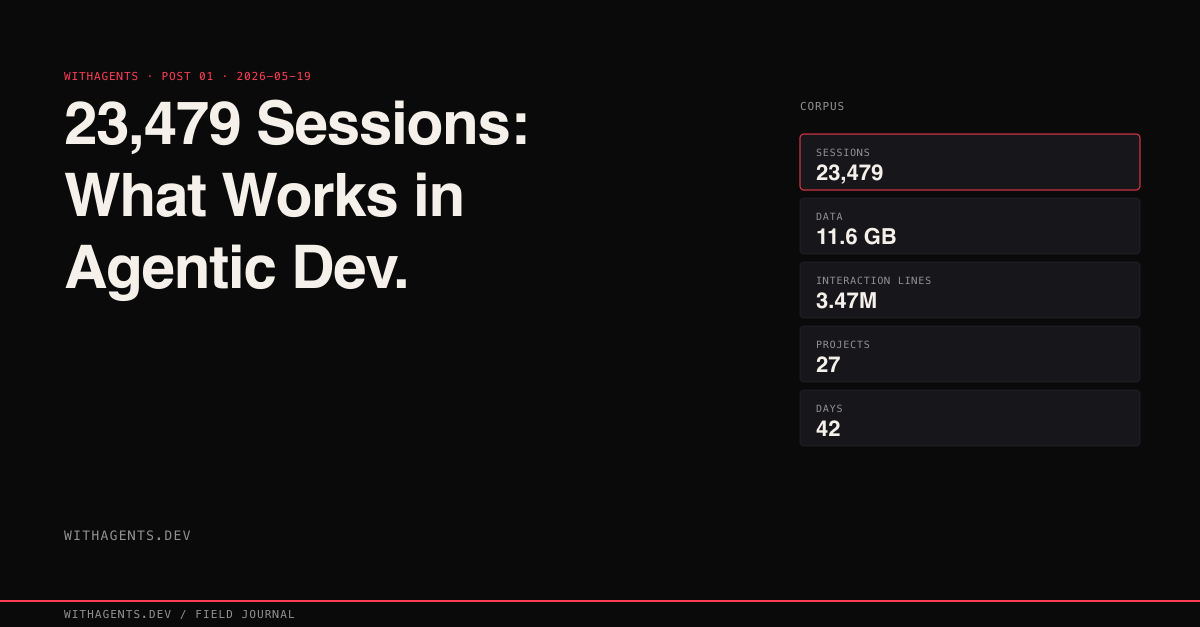
I averaged 559 AI coding sessions per day for 42 days straight. Not prompts. Sessions. Each one a self-contained agent with its own context window, its own task, its own tools.
23,479 total. 3,474,754 lines of interaction data across 27 projects. This series is what I learned.
Here's the short version: AI agents fail in predictable ways. They forget across sessions. They declare victory without evidence. They build features that look correct but do nothing. They pick expensive models for trivial tasks. They corrupt each other's work when they edit the same file. Every system I built over those 42 days — consensus gates, functional validation, cross-session memory, orchestration loops, enforcement hooks — exists because one of those failures hit me in production. Building with agents. Building tools for agents. Every claim traces to a real session. Every system backed by a companion repo you can clone and run.
The Numbers
23,479 sessions. I started 4,534 of them. The other 18,945 were agents spawning agents. An orchestrator delegates to a reviewer, the reviewer spawns a verifier, the verifier reports back up the chain. That's a 1:4.2 ratio. Every time I kicked off a session, the system spawned roughly four more on its own.
The tool leaderboard tells you what agents actually do with their time:
Read leads everything. 87,152 file reads versus 19,979 edits, a 4.4:1 ratio. Throw in Bash (82,552, mostly commands to understand state) and Grep (21,821 searches), and the picture gets starker: agents spend roughly 80% of their tool invocations understanding code and 20% changing it.
That ratio is the thesis of this entire series. Agents that read before they write produce fewer regressions than agents that jump straight to editing. The most productive thing an AI agent does isn't writing code. It's understanding the code that already exists.
“Agents aren't generators. They're readers that occasionally write.”
The coordination column is where things get wild. 2,827 Task spawns. 4,852 TaskUpdates. 2,182 TaskCreates. 1,720 SendMessages. That's an entire organizational layer. Agents creating teams, assigning work, reporting status. None of that existed when I started. The 929 inline Agent calls are ad-hoc delegation: an agent decides mid-task that it needs a specialist and spins one up on the spot. I didn't design that behavior. It emerged.
Five Failure Modes
Every system in the rest of this series exists because something broke. These five failure modes showed up in the first week and never stopped.
Amnesia is fixed by a cross-session memory store that records observations and re-injects them into future contexts. That system reduced repeated mistakes by 73% across the projects where it was deployed (Post 12).
Confidence without evidence is fixed by functional validation. No mocks, no test files. Build the real system, run it, exercise it through the actual UI, capture screenshots. Across all sessions, the block-test-files hook fired 642 times, preventing agents from writing tests that mirror their own assumptions instead of exercising real features (Post 3).
Completion theater is caught by the three-layer validation stack: 7,985 iOS simulator MCP calls (taps, gestures, accessibility queries, screenshots) and 2,068 browser automation calls (clicks, navigations, screenshots). Real buttons. Real forms. Real validation.
Wrong model for the job is fixed by three rules: lookups go to Haiku, implementation goes to Sonnet, architecture review and complex debugging go to Opus. No machine learning. No classifier. Just three rules (Post 7).
Coordination failures are fixed by file-ownership maps with glob patterns. Two agents literally can't edit the same file. That system and its 2.3x speedup over sequential execution is the subject of Post 2.
From Autocomplete to Operating System
The turning point was a framing shift: stop using AI as autocomplete and start treating it as a team of specialized workers.
Autocomplete operates inside a single context window. A team operates across multiple context windows with coordination protocols between them. The context window isn't just a limitation. It's an architecture boundary. Each agent gets a fresh window, a specific role, and a defined scope. The orchestrator coordinates across those boundaries using the filesystem, not shared memory.
4,534 human-initiated sessions versus 23,479 total tells the story: 81% of all sessions were agents spawning other agents. The coordination infrastructure (2,827 Task spawns, 4,852 TaskUpdates, 2,182 TaskCreates, 1,720 SendMessages) is an organizational layer running on top of Claude Code. I didn't plan it that way. It emerged because single-agent workflows kept hitting the five failure modes above.
Here's what that looks like in practice. Session 33771457 in the ils-ios project: the orchestrator needed to consolidate five incomplete iOS specifications into one production spec. It spawned 13 different team configurations over the course of the session. First a design team — one architect and three validators. The architect drafted; the validators reviewed independently and voted. When consensus was reached, the orchestrator dissolved the team and created an implementation team: one executor, three new validators. When implementation gates passed, a final consensus checkpoint team produced the unanimous PASS/FAIL verdict. Eighty agent operations total. I typed one sentence to start it.
Four Patterns That Survived
Across 23,479 sessions, four patterns survived contact with real codebases. Everything else? Good ideas that didn't hold up.
The consensus-gate pattern caught the +=-vs-= bug that had been hiding for three days. Alpha flagged the operator as inconsistent with the API's full-message response format. Bravo flagged the index reset as a state management hazard. Lead flagged both as violations of the streaming module's own documentation comments. Three reviewing agents, three different lenses, one root cause.
Functional validation caught a stale .next cache bug that next build said didn't exist. The agent ran 674 Playwright tool calls in a single validation pass. I'm still annoyed about that one — I'd spent two hours blaming my code before the agent proved it was a build cache issue.
Fresh context wins over accumulated context. Have you ever watched an agent confidently reference code it read 30 minutes ago that's since been rewritten by another agent? I have. The discipline is short-lived agents with one job each.
Filesystem persistence is what lets agents collaborate without shared memory. VG1.2 from session ad5769ce: “EventBus emits events” — evidence: curl emit&count=10 returns {“emitted”:10, “subscriberCount”:1, “ringBufferSize”:10}. Not “it works” but “here is the exact JSON proving it works.”
The Economics
The ils-ios project is the largest in the dataset: 4,241 session files, 1,563,570 lines of data, 4.6GB. 149 Swift files, 24 screens, a macOS companion, 13 visual themes. Total Claude API cost: approximately $380.
That cost only makes sense with model routing:
82% savings. A project with 200 consensus gates costs $30 with routing versus $168 without. Three rules: lookups go to Haiku, implementation goes to Sonnet, architecture review and complex debugging go to Opus.
RALPLAN, the adversarial planning system, showed why planning consensus pays for itself. A Supabase auth migration got decomposed into 14 tasks by the Planner. Looked clean. The Architect vetoed it. Supabase Row Level Security policies reference auth.uid(), which returns Supabase's internal user ID, not a custom JWT's subject claim. Seven of the 14 tasks assumed RLS compatibility. They would've compiled. They would've passed type checks. They would've failed silently at runtime, allowing unauthorized data access. Three rounds of adversarial review caught it. Cost of those review rounds: under $2. Cost of shipping a silent auth bypass: I don't want to think about it.
What the Rest of the Series Covers
The posts are organized by problem, not chronology. Post 2 starts with the bug that started everything: line 926, += instead of =, and the three-agent consensus system that caught it.
Each post has a companion repo. Each repo has working code. Each claim traces back to one of 23,479 real sessions generating 3,474,754 lines of data over 42 days. No fabricated examples. No mock data. Just what actually works when you run AI agents at scale.
What You’ll Walk Away With
- 01A consensus gate framework that catches bugs single-agent reviews miss ($0.15 per gate)
- 02A functional validation protocol that replaces unit tests with real UI interaction
- 03An orchestration system that coordinates multiple agents without file conflicts
- 04A cross-session memory store that keeps agents from repeating the same mistakes
- 05A model routing strategy that cuts API costs by 82%
- 06A prompt engineering stack that composes seven layers of context
- 07Enforcement hooks that stop agents from cutting corners
Next post starts with the bug that started everything. Line 926, += instead of =, and the three-agent consensus system that caught it.
Continue the series
- 02Foundation3 Agents Found the Bug 1 Agent MissedWhy multi-agent consensus catches what solo review cannot
- 03FoundationI Banned Unit Tests and Shipped FasterWhy functional validation replaced testing when AI writes the code
- 04FoundationThe Five-Layer Streaming BridgeToken-by-token Claude streaming on iOS — after four failed architectures