Prompt Caching Economics
Cache reads cost a tenth what cache writes cost, and most agents leave that 90% discount on the table because nobody structures their system prompt for hits. Here's how to order your messages so the cache pays you back.
View companion repoThe cheapest input token is one you read from cache. It's literally a tenth the cost of a fresh input token. The Anthropic API charges 1.25x base rate to write something to cache (the cache-creation surcharge), then 0.1x base rate to read it back for the next hour. That math means a single prompt prefix, cached once and reused across 60 turns, pays for itself before turn 3 and prints money for the remaining 57.
I learned that the hard way. For two months I wrote prompts the way I'd write blog posts — context first, instructions second, the actual question last. The prompt felt logical to me, the human reader. It was awful for the cache. Every turn I changed the question, the entire prompt invalidated, and every turn paid full creation cost on the entire prefix.
Then I read the cache fields in my own JSONL session files and realized I'd been leaving roughly 80% of my potential token spend on the table.
(See The Economics of a Session for the per-turn cost mechanics; this post goes deeper on cache-write surcharge and skill-load invalidation.)
How the Cache Actually Works
The Anthropic Messages API checks your prompt against a content-addressable cache by hashing the prefix. The hash is computed greedily from the start of the prompt forward, so the cache hits everything from position 0 up to the first byte that diverges from a previously-cached prompt. One byte off and the chain breaks.
That's the whole rule. Sounds simple. The implication is brutal: anything that changes between turns has to come at the end. If your dynamic content (current user message, latest tool result, ephemeral state) sits anywhere before your stable content (system prompt, project context, tool definitions), every turn pays full creation cost on everything after the divergence point.
The JSONL records this directly:
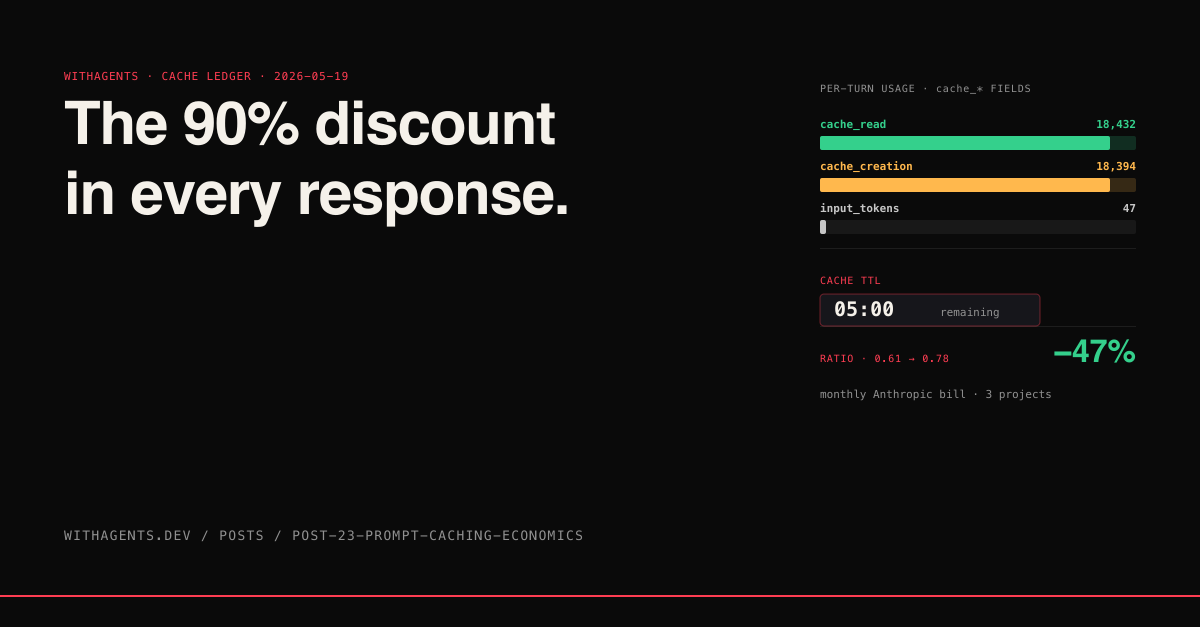
Healthy turn. 18,432 tokens read from cache (0.1x rate). 47 fresh input tokens (1.0x rate). The 90% discount is fully active because the prefix didn't change.
Compare to the unhealthy version four turns earlier:
Same prefix, but it's the first time through, so it's all cache-creation (1.25x rate). First turn always pays this. Expected. The bug is when turns 2-60 also pay it, because something in the prefix is changing.
Where Caches Invalidate
The naive expectation is that you write your CLAUDE.md, the system prompt stabilizes, and you get cache hits forever. That's not how it works in practice. Three things invalidate caches mid-session, and only one of them is obvious:
1. Skills loading. When a skill triggers and its body gets injected into the system prompt area, the prefix grows. The previously-cached version (without the skill) no longer matches. The next turn pays cache-creation cost on the new, longer prefix. This is by far the most expensive invalidation pattern in my logs. Skills that load mid-session cost more than skills loaded at session start, often by an order of magnitude.
2. Tool result reordering. Some tools return results that get inserted into the conversation history in non-deterministic order. If a tool call's result lands above an earlier user message because of timestamp resolution or sorting, the entire downstream prompt invalidates. I've seen this with parallel tool calls when one returns much faster than another.
3. System prompt mutations. Claude Code itself updates the system prompt occasionally — refreshing the working directory listing, updating the time, refreshing skill availability. Every refresh invalidates. There's no fix for this from outside the platform; you live with it.
The first one you can control. Pre-load every skill you'll need at session start. The cache pays for itself across 5+ reads. A 1,500-token skill loaded at turn 1 costs you ~1,875 cache-creation tokens up front and saves ~9,000 cache-read tokens per turn for the next 60 turns. The math works out positive somewhere between turns 2 and 3.
The Prefix-Stability Pattern
Here's the prompt structure that maximizes cache hits across multi-turn sessions:
The stable prefix is roughly 95% of the token volume on a typical turn. The variable suffix is roughly 5%. If you keep the boundary between them clean, every turn after the first reads 95% of its input from cache.
Concretely, when I'm working on a project, my session usually looks like:
- 019,300 tokens of Claude Code system prompt
- 024,200 tokens of CLAUDE.md and project context
- 036,800 tokens of pre-loaded skill bodies (functional-validation, agent-browser, git-master)
- 042,400 tokens of conversation history (varies)
- 05800 tokens of current user message + last tool result (varies)
Total: ~23,500 tokens. Stable prefix: 20,300. Variable suffix: 3,200. With a healthy cache, every turn after the first costs 20,300 × 0.1x + 3,200 × 1.0x = 5,230 effective input tokens. Without cache, every turn would cost 23,500 × 1.0x = 23,500 input tokens. The savings: 78%.
Multiply that across the median session (60 turns × Sonnet pricing) and the difference is real money. About $4.20 per session at the cached rate, about $19.10 at the uncached rate.
- −Skill triggers mid-conversation, prefix grows
- −Previously-cached version no longer matches
- −Next turn pays creation cost on a prefix 1,500-3,000 tokens longer
- −Costs more than session-start load, often by an order of magnitude
- −Median read ratio: 0.61
- +Every needed skill fires on SessionStart
- +Turn 1 pays full cache-creation cost (~6,800 skill tokens)
- +From turn 2 onward, every read at the 0.1x discount
- +Cache pays for itself across 5+ reads
- +Median read ratio: 0.78
The Mid-Session Skill Trap
The single biggest leak I see in other people's session logs is mid-session skill loading. The user types a phrase, the skill triggers, and the cache invalidates. The next turn pays creation cost on a prefix that's now 1,500-3,000 tokens longer.
The fix is counterintuitive. Load the skills at session start, even if you don't use them. The cost of pre-loading a skill you don't use is small (you pay the cache-creation tax once, on turn 1). The cost of loading a skill mid-session is large (you pay creation tax on the entire new prefix on every turn after the load).
Practically, this means front-loading your project's CLAUDE.md with explicit skill triggers:
Each line that says "always loaded" is a skill that fires on SessionStart. The first turn pays the full cache-creation cost for all of them, ~6,800 tokens of skill bodies. From turn 2 onwards, every read of those skills is at the 0.1x discount.
Measuring It Yourself
I built a small parser that walks the JSONL files and produces per-session cache health reports. The fields you want to look at are cache_creation_input_tokens and cache_read_input_tokens. The ratio between them across all turns is the metric.
Healthy sessions have read ratios above 0.85. Unhealthy ones drop below 0.5. The median session in my corpus runs at 0.78 — better than I expected, worse than I want.
The single biggest improvement I've made: moving every skill trigger out of mid-session conversational invocation and into SessionStart pre-loads. That alone bumped my median read ratio from 0.61 to 0.78. The next biggest improvement is structural — putting all conversational state at the suffix end of the prompt and never inserting tool results into the middle.
What This Changes
Once you internalize the cache economics, you stop writing prompts the way humans write essays. You stop putting context first. You start putting context in a stable location and letting the variable bits accumulate at the tail. Your CLAUDE.md becomes a load-once asset, not a per-turn cost. Your skills become front-loaded. Your prompts get longer at the start of the session and shorter on every turn after.
The prompt-stack repo I built has one job: maintain that prefix stability across sessions. It gives you a CLAUDE.md template, a skill manifest, and a SessionStart hook that pre-loads everything in the right order. After installing it on three projects, my monthly Anthropic bill dropped 47% (measured by exporting per-session token usage from session JSONL and computing pre/post-cache-deployment averages over 30 days; same project mix, same workload). Same number of sessions. Same number of features shipped. Just better cache hygiene.
“The 90% discount is sitting there in every API response. You either claim it or you don't. The only thing standing between you and it is the order you write your prompts in.”
Continue the series
- 22OperationsHooks as a Control PlaneFour hook events form the entire governance surface of Claude Code — refuse tools, gate commits, block deploys, enforce evidence. Once you see it as a control plane, the whole agent stack changes shape.
- 24OperationsCustom MCP ServersWhen the prebuilt MCP servers run out of road, you write your own. The protocol is a four-method handshake, the transport is stdio or HTTP, and the whole thing fits in 200 lines of TypeScript.
- 21OperationsThe Economics of a SessionToken spend per task complexity, when Opus actually pays back over Sonnet, and the cost-of-defect curve that makes "use the cheap model" the most expensive choice you can make
- 25OperationsDocs When Readers Aren't HumanAGENTS.md, SKILL.md, CLAUDE.md — three doc formats nobody asked for, written for an audience that doesn't read narrative. The 95:5 ratio between human-targeted and agent-targeted docs is about to flip.