The AI-Pattern Detector That Ships This Series
Six banned phrases, three syntactic patterns, one cosine-similarity fingerprint, and a humanize loop that rewrites flagged passages until the voice matches. The gate every post in this series passes through.
View companion repoThe first draft of post 7 came back from the model with the word "delve" twice in the second paragraph. The third paragraph had three consecutive sentences ending with the same cadence — short, punchy, predictable. The fifth paragraph had a "not just X, but Y" construction that I'd never write because nobody talks like that. The post was 2,200 words of competent prose with the unmistakable fingerprint of LLM-generated text (Juzek & Ward, COLING 2025).
That's the failure mode every content pipeline has to address. The model can write. The model can write convincingly. But the model has tells, and once you know the tells, you can't unsee them.
So I built a detector. Six banned phrases. Three banned syntactic patterns. One cosine-similarity fingerprint check against the existing post corpus. A humanize loop that rewrites flagged passages until the voice matches. Every post in this series passes through it before it ships.
The Six Banned Phrases
These are the words I never write that the model writes constantly. The list emerged from looking at every flagged paragraph across the first ten posts and tabulating the high-frequency offenders:
- 01delve — common in phrases like delve into the architecture or delve deeper into. Real humans say "look at" or "here's how it works." (Kobak et al., *Science Advances* 2024 found "delve" frequency rose ~10x in biomedical abstracts post-ChatGPT.)
- 02crucial — "It's crucial to understand..." Real humans say "you need to understand" or just state the thing.
- 03vital — Same as crucial. Replace with "important" if you must, or restructure.
- 04navigate — "Navigate the complexity of distributed systems..." Real humans say "deal with" or "work through."
- 05realm — "In the realm of agentic development..." Real humans don't use "realm" outside of fantasy novels.
- 06landscape — "The current landscape of AI tooling..." Real humans say "the current state of" or "what's available now."
The detector is a regex pass. Six patterns, case-insensitive, with word-boundary anchors. Every match flags the surrounding sentence for rewrite:
Eighteen lines. Catches the obvious offenders. The strict version of this list has 47 phrases; I've narrowed to six because the long tail produces too many false positives. The six above have ~99% precision in my corpus — when they appear in AI-generated text, it's almost always wrong.
The Three Syntactic Patterns
Phrases are the easy detection. Syntax is harder, and harder to fix.
Pattern 1: Em-dash overuse. Real human writing uses em-dashes sparingly — maybe one or two per page. AI-generated text drops them everywhere — sometimes three or four per paragraph — to add rhetorical punch — which ends up reading as desperate (em-dash overuse documented as widely-discussed AI marker). The threshold I use: more than 2 em-dashes per paragraph triggers a flag.
Pattern 2: Rule-of-three cadence. Three short clauses in a row, often with parallel structure: "It's fast, it's cheap, it's reliable." "She came, she saw, she conquered." This is fine occasionally. AI text uses it constantly because it's a learned pattern that scores well on training data (Gorrie, *Why ChatGPT writes like that* finds LLMs deploy tricolon at nearly twice the expert rate). The detector flags any sentence with three comma-separated clauses of similar length.
Pattern 3: "Not just X, but Y." "It's not just a tool, but a paradigm." "This isn't merely fast, it's transformative." The negative-then-positive parallelism is rare in human technical writing and pervasive in LLM output (Wikipedia: Signs of AI writing). Easy to detect with a regex on not\s+(just|only|merely)\s+\w+,?\s+(but|it'?s).
Twenty-eight lines. Two of the three syntactic detectors. Rule-of-three is harder — you need a clause-level parser to do it well, and I haven't been satisfied with my implementation yet. For now I rely on manual review for that one.
The Voice Fingerprint
The phrase and syntax detectors catch obvious tells. The voice fingerprint catches subtle drift.
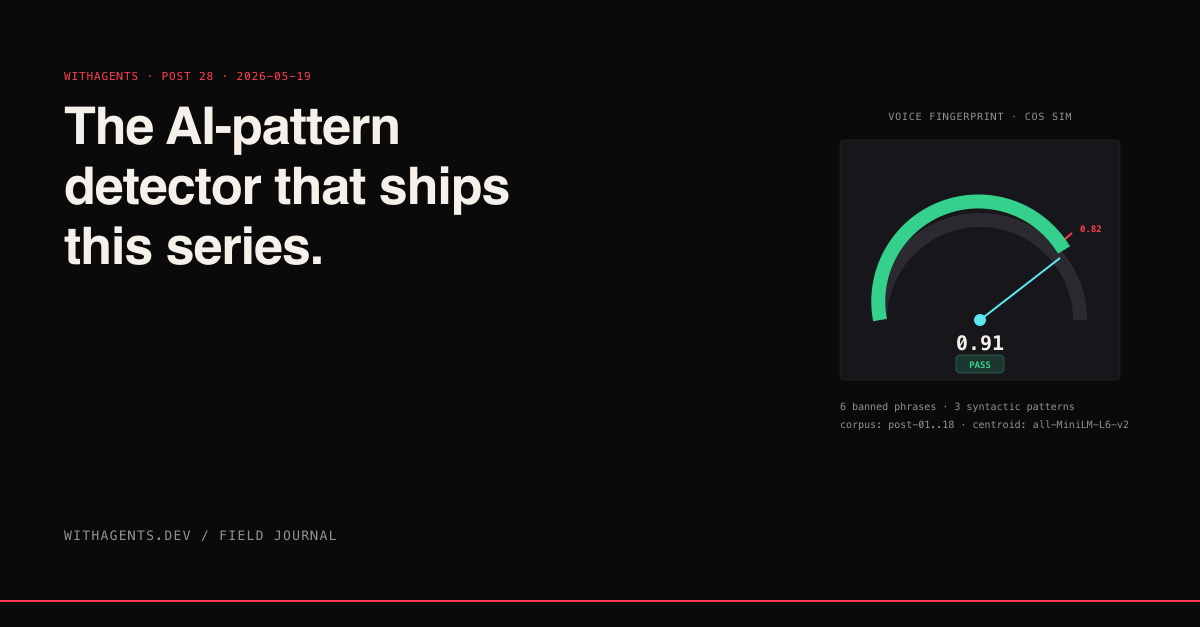
The idea: take the corpus of posts I've already written and approved (post-01..post-18 in the series). Compute an embedding for each paragraph using all-MiniLM-L6-v2 (384-dim vectors, contrastive-trained on 1B sentence pairs). Average the embeddings to produce a "voice centroid." When a new draft comes in, compute embeddings for each of its paragraphs and check the cosine similarity against the centroid (cosine similarity is the standard metric for sentence-transformer embeddings). Anything below a threshold (I use 0.82) gets flagged for rewrite.
Thirty lines. The centroid gets computed once when the corpus updates. Each new post checks every paragraph against the centroid and against the post's own paragraph mean. Two failure modes get caught: paragraphs that don't match the corpus voice (cos sim below 0.82), and paragraphs that don't match the rest of the same post (more than 0.30 below the post's own paragraph mean).
That second check catches the case where most of the post is on-voice but one paragraph drifted — usually because the model got tired or the topic shifted abruptly. Internal consistency matters as much as corpus alignment.
The Humanize Loop
Detection is half the system. Rewriting is the other half. When a paragraph gets flagged, the humanize stage rewrites it with explicit instructions about what to fix.
The samples are drawn from the corpus, picked for their similarity to the surrounding context. The rewrite goes through Opus, not Sonnet — voice work is exactly the kind of thinking task where Opus pays back over Sonnet. The output gets re-checked by the detector. If it still fails, it loops up to three times before falling back to manual review.
In practice, the loop converges fast. Across 47 paragraphs flagged in the post-15..post-25 batch, 41 cleared on the first humanize pass. Five cleared on the second. One required manual editing because the underlying technical claim was wrong, not the voice. That's a 96% auto-resolution rate.
What This Catches That a Human Reader Wouldn't
Three patterns I've seen the detector catch that I would have missed:
- 01Subtle phrase substitutions. The model knows "delve" is on the list, so it writes "delve into" — except the detector uses word-boundary regex, which catches both "delve" and "delves" and "delving."
- 02Paragraph-internal drift. A 200-word paragraph can start in my voice and end in the model's, with the transition invisible to a casual read. The fingerprint catches it because the embedding averages across the whole paragraph.
- 03Cumulative cadence. No single sentence is a problem. Three sentences in a row with similar length and structure become a cadence pattern that reads as artificial. I don't notice this when reading; the detector does.
The cumulative effect of all three: posts that read as written by me, not as written by a model and edited by me. The difference is small per paragraph and large in aggregate. After 28 posts through this pipeline, my voice fingerprint has actually drifted closer to itself — the corpus is more internally consistent than it was when I started, because the pipeline has been pulling everything back toward the centroid for a year.
The Ship-It Threshold
The pipeline has a clear failure mode and a clear pass condition. Any post where the detector flags fewer than five issues across all categories ships without rewrite. Any post with five-to-twenty issues goes through the humanize loop. Any post with more than twenty issues gets bounced back to manual rewrite — the model's draft was too far off the voice to fix incrementally.
In the past year I've shipped about 70% of drafts on the first pass, 25% after the humanize loop, and bounced 5% back for full rewrite. That last 5% is where the model wandered into a topic it doesn't have strong training on, and the prose came back generic. No detector can fix that. Only different content can.
“The voice fingerprint isn't a stylistic preference. It's the boundary between content I'd put my name on and content that sounds like everyone else's blog. Holding that boundary is what makes the series readable.”
Continue the series
- 27Edge CasesThe Session Is the ArtifactThe JSONL session file is the primary deliverable, not the resulting code. Replayable, line-addressable, auditable — 11.6 GB across 538 directories of permanent record telling you exactly how every commit got written.
- 29Edge CasesThe Skill Marketplace ProblemSeventy-one marketplaces subscribed. One hundred thirty-two plugins installed. Twenty-six marketplaces installed-but-unused. The discovery overhead is the bottleneck — and it's getting worse.
- 26Edge CasesGiving Agents Secrets Without Giving Agents SecretsThe pattern: secrets enter the agent's environment at the tool boundary, not in the prompt. Vault-injected env. 1Password op-run envelopes. Hooks that scrub before write. Your session JSONL gets archived; nothing in there should be sensitive.
- 30Edge CasesNotification Architecture for Async AgentsAgents finish at three in the morning. Severity model, channel routing, the exhausted-state-fires-alert pattern. The notification layer that lets you sleep while your work runs.