Notification Architecture for Async Agents
Agents finish at three in the morning. Severity model, channel routing, the exhausted-state-fires-alert pattern. The notification layer that lets you sleep while your work runs.
View companion repoThe first time I left a Claude Code session running overnight, it finished at 3:47 AM with a question I would have answered immediately if I'd been awake. The agent waited, idle, until I sat down at my desk at 8:15. Four and a half hours of wall-clock time wasted because the agent had no way to reach me.
I built the notification layer that night. Not because I expected to be reachable at 3:47 AM — but because the agent should have known whether to wait for an answer or push forward with a default. And if it was going to wait, it should have at least sent something to my phone so I'd know in the morning that work was blocked.
Async agent workflows have a notification problem that's structurally different from the human-software problem. The agent isn't trying to alert you to a UI event. It's trying to coordinate with you across hours of asynchronous work. The right answer isn't "more notifications." The right answer is a routing model that knows when to interrupt, when to log, and when to act on its own.
The Severity Model
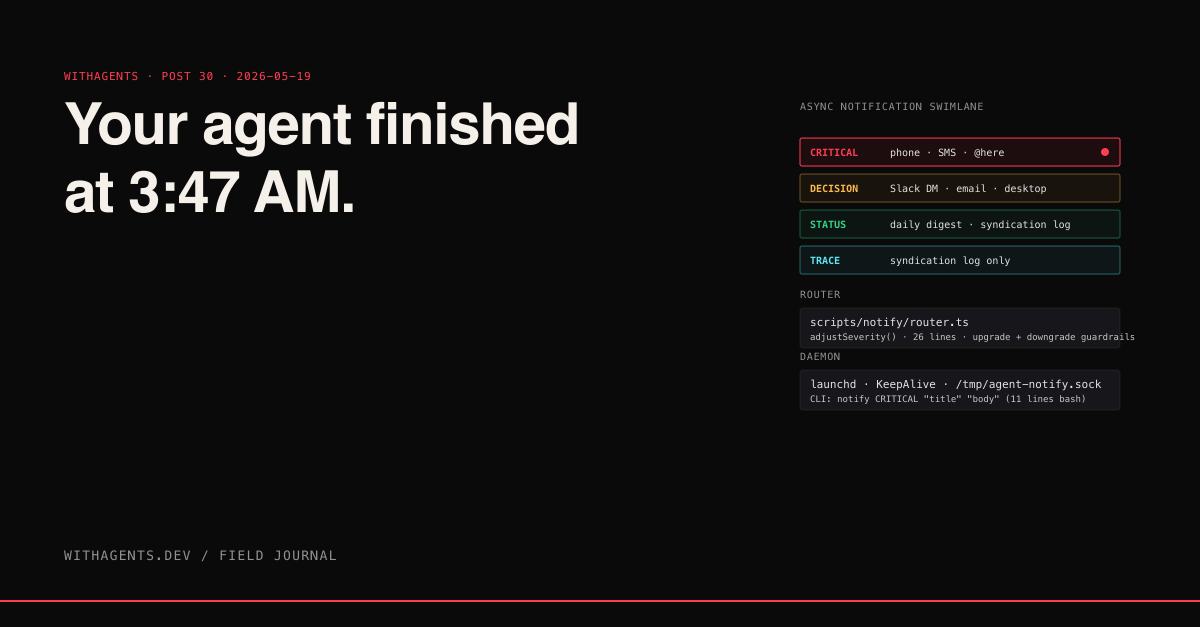
Every notification has a severity. The model I use has four levels:
- 01CRITICAL — production is broken, security event, data loss imminent. Wake me up. Phone push, SMS, Slack DM with @here.
- 02DECISION — agent is blocked, needs a human answer to proceed. Sleep through it, but show me at first opportunity. Slack DM (no @here), email, desktop notification.
- 03STATUS — agent finished a long-running task, no action required. Goes into a digest. Daily email.
- 04TRACE — agent passed a checkpoint or hit a milestone. Logged only. No notification, just a record.
The mapping isn't ambiguous. CRITICAL is for things that need a human in under an hour. DECISION is for things that need a human eventually. STATUS is for "you'll want to know this happened." TRACE is for the audit trail.
The agent classifies its own notifications. The classification isn't perfect, so the routing layer has guardrails — things that look like CRITICAL but came from a known-noisy source get downgraded automatically. Things that look like STATUS but contain certain keywords ("rollback," "secret leaked," "deletion") get upgraded automatically.
Twenty-six lines. Catches the misclassifications. The agent flagging its own work as CRITICAL because it was struggling, when really it was just a flaky lint pass — that gets downgraded. The agent flagging a secret leak as merely DECISION because it didn't realize the keyword was present — that gets upgraded.
The Channel Routing
Each severity maps to a set of channels. The mapping looks like:
The channels themselves are pluggable. Phone push goes through Pushover. SMS goes through Twilio. Slack uses bot tokens. Email goes through Resend. Desktop uses macOS Notification Center via osascript. Each channel is a small TypeScript module exposing a send(notification) function:
Twenty-two lines per channel. Add a new one by writing another module that exposes the same send(n) interface. The router doesn't care about the implementation; it just dispatches to whatever channels the severity routing yaml lists.
The launchd Setup
The notification layer runs as a long-lived process under launchd on macOS (the equivalent of systemd on Linux). It listens on a Unix socket. Agents send notifications to the socket; the daemon handles routing.
Loaded with launchctl load ~/Library/LaunchAgents/com.nick.agent-notify.plist. Auto-restarts on crash. Logs to a known location. Survives reboots.
Agents send notifications by writing JSON to the socket (via `nc -U` for Unix-domain stream sockets):
Eleven lines. Easy to invoke from any agent context: notify CRITICAL "build broken" "main is failing on commit abc123".
The Exhausted-State Pattern
The most important pattern in agent notifications is what fires when the agent gets stuck. Not when it succeeds — when it gives up.
The Stop hook on every long session fires a notification with the agent's exhaustion summary: how many turns it ran, what it accomplished, what it left undone, what blocked it. If the work completed, severity is STATUS. If the agent stopped because it was waiting for a human decision, severity is DECISION. If the agent stopped because it hit a hard error it couldn't resolve, severity is CRITICAL.
Twenty-eight lines. Runs on every session-end. The classification is heuristic but conservative — when in doubt, escalate. I'd rather get a false-positive CRITICAL than miss a real blocker.
The Digest Pattern
STATUS notifications are noisy if delivered individually. Twenty agent runs in a day produce twenty success notifications, each one trivially true and individually uninteresting. The digest pattern aggregates them.
A daily cron job at 8 AM walks the syndication log, groups STATUS notifications by source, and sends a single digest email:
Thirty lines. Produces a markdown digest with sections per source, top-five items each, count of overflow. Resend delivers it at 8 AM. I read it with my coffee. Most days it's a quick scan — the agents did what they should have, no surprises.
What I Don't Want
Three anti-patterns I've explicitly avoided:
- 01Real-time notifications for everything. A Slack DM for every successful build is noise. The build is supposed to succeed. Notify me on the failures, digest the successes.
- 02Notifications without context. "Build failed" without a link to the run, the commit, the relevant logs is useless. Every notification has a context_url field. The mobile push opens to the link directly.
- 03Notifications that aren't actionable. "Agent ran for 47 minutes" is information, not action. STATUS at most. The CRITICAL channel is reserved for things I can act on right now.
The reverse anti-pattern is also real: notifications that are too aggressive about classifying things as CRITICAL. After a week where I got woken up four times for issues that turned out to be lint failures, I added the DOWNGRADE_SOURCES list. Now lint failures stay STATUS unless they keep failing.
The Sleep Test
The simplest check for whether the notification layer is working: how many times has it woken me up unnecessarily in the past month? If the answer is zero, I might be filtering too aggressively. If the answer is more than twice, I'm filtering not aggressively enough.
The current rate, after six months of tuning, is about one false-positive CRITICAL per month and zero missed real CRITICALs (that I'm aware of — I'd know because the issue would still be broken when I woke up). That's a tolerable rate. The cost is the tuning effort. The benefit is being able to leave agents running overnight without anxiety about what I'll find in the morning.
“The agent that finished at 3:47 AM and waited until 8:15 for an answer — that doesn't happen anymore. If it needs a decision, my phone buzzes at 8:00 with a DECISION-severity notification. The rest is silence, which is what async agent work needs to be sustainable.”
Continue the series
- 29Edge CasesThe Skill Marketplace ProblemSeventy-one marketplaces subscribed. One hundred thirty-two plugins installed. Twenty-six marketplaces installed-but-unused. The discovery overhead is the bottleneck — and it's getting worse.
- 31Edge CasesDrift DetectionSpecs and code diverge silently. The 60-day audit pattern, the four-class taxonomy (dead, drifted, lying, fine), and what I do every quarter to make sure my docs still describe what my code actually does.
- 28Edge CasesThe AI-Pattern Detector That Ships This SeriesSix banned phrases, three syntactic patterns, one cosine-similarity fingerprint, and a humanize loop that rewrites flagged passages until the voice matches. The gate every post in this series passes through.
- 32Edge CasesThe 529 CascadeAnthropic returns 529 (overload) intermittently. Naive retries themselves consume the bucket and storm the API a hundred times over. The retry policy that costs less, not more.