194 Parallel Agents, Zero Merge Conflicts
Git worktrees give each AI agent its own filesystem — a five-stage pipeline makes sure they all come back together
View companion repoTwo Claude agents had been working on the same codebase for twenty minutes. Agent A refactored the storage module. Agent B added caching to (you guessed it) the storage module. Neither knew the other existed. I stared at the terminal full of merge conflicts and felt that familiar sinking feeling. The diff was a disaster.
That's when I stopped thinking about AI agents as 'faster developers' and started thinking about them as concurrent processes that need isolation guarantees. Better prompts wouldn't fix this. Smarter conflict resolution wouldn't fix this. Making conflicts structurally impossible would fix this.
The mechanism that made them structurally impossible: file-scope declarations enforced before any agent starts working. Each spec declares exactly which files its agent is allowed to touch. If two specs overlap, the orchestrator rejects the second one at task creation time, not at merge time. Combine that with git worktrees (each agent gets its own physical working directory on its own branch) and two agents literally cannot edit the same file at the same time. The filesystem enforces what prompts can't.
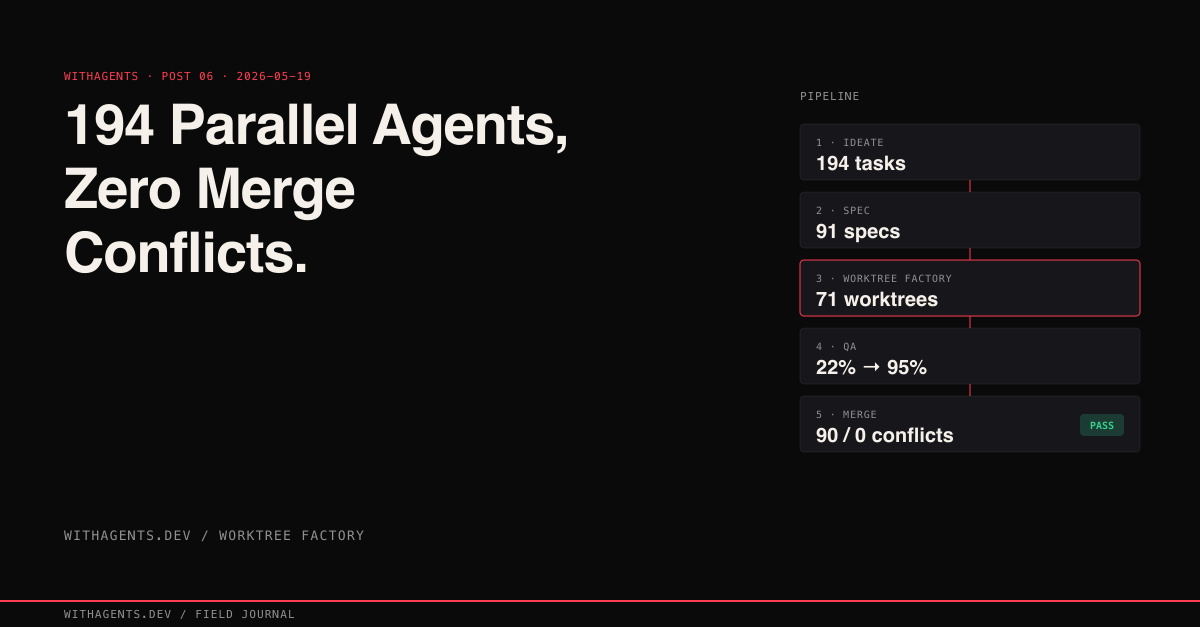
The pipeline I built around this turned weeks of serial work into something 194 agents could build in parallel without stepping on each other once. Ideation, spec generation, isolated execution, independent QA, priority-weighted merge. Five stages. Zero conflicts.
Why Branches Don't Cut It
The obvious first attempt is branches. Agent A works on feature/auth, Agent B works on feature/cache. Clean separation, right?
Nope. Branches share a working directory. If Agent A is on feature/auth and Agent B needs to switch to feature/cache, Agent A's uncommitted changes get clobbered. You could commit before switching, but now you're serializing parallel work. That defeats the whole point.
Even with separate clones, you pay a steep cost. A full clone of a large repo takes minutes and gigabytes. Worktrees? Seconds. They share the object store. The .git directory stays shared; only the working tree gets duplicated. For a 500MB repo, 194 full clones would eat ~97GB. 194 worktrees consume a fraction of that.
That single command gives you a physically separate directory with its own branch, its own index, its own HEAD, all backed by the same repository. Agent A works in /worktrees/feature-auth/. Agent B works in /worktrees/feature-cache/. Different directories, different branches, same git history. No filesystem contention. No accidental overwrites.
Creating one worktree is trivial. The engineering challenge? Managing 194 of them through a complete lifecycle: creation, spec injection, agent execution, quality review, priority-ordered merge, and cleanup. That's what the auto-claude-worktrees pipeline does.
The Five-Stage Pipeline
I didn't just 'create worktrees and run agents.' I built a five-stage pipeline where each stage feeds the next, and the whole thing runs with minimal human intervention.
From the Awesome List project (my stress test), here are the numbers:
194 tasks generated. 91 turned into specs (the rest got deferred or were duplicates). 71 worktrees provisioned and executed. Zero merge conflicts when those branches came back together.
Stage 1: Ideation — Let the Agent Scope the Work
Here's a counterintuitive move: let the AI agent decide what to build. Not the high-level vision, that's still mine. But the granular task decomposition? An Opus agent analyzing the full codebase produces better task boundaries than I do manually. I've tried both. It's not close.
The ideation agent examines directory structure, file contents, and architecture patterns, then generates a task list. Each task gets four things: a unique identifier, a scope boundary (which files it touches), dependencies (which tasks must finish first), and a priority ranking.
I deliberately let ideation over-generate. Why? Producing 194 task descriptions costs a fraction of executing even one of them. The downstream QA pipeline filters what shouldn't ship. It's cheaper to generate 194 and execute 91 than to carefully curate 91 up front.
Stage 2: Spec Generation — The Bottleneck Nobody Expects
Raw task descriptions aren't enough for autonomous agents. 'Implement OAuth flow' is too vague. An agent will make assumptions about endpoints, token formats, error handling, and those assumptions will conflict with whatever another agent assumed about the same system.
The spec generator turns each task into a detailed blueprint:
- 01Objective: Single-sentence end state
- 02Files in scope: Explicit list of files to create, modify, or delete
- 03Implementation steps: Ordered sequence of changes
- 04Acceptance criteria: Concrete, verifiable conditions
- 05Risk notes: Known pitfalls and edge cases
Here's the data model from the actual codebase:
The files_in_scope field is everything. It declares exactly which files this task can touch. When two specs declare overlapping file scopes, the orchestrator catches it before any agent starts working. Conflict prevention at the cheapest point (task creation) instead of the most expensive point (merge time).
Here's the key lesson from running this at scale: specs are the bottleneck, not execution. A precise spec passes QA on the first attempt. A vague spec fails QA, gets sent back for fixes, and burns two extra sessions. That 22% first-pass rejection rate? Almost entirely traceable to specs that weren't specific enough about edge cases or error handling.
Stage 3: The Worktree Factory
This is the core. For each spec, the factory runs a four-step lifecycle:
- 01Create worktree — git worktree add from main with a dedicated branch
- 02Inject spec — Write the spec as both human-readable markdown and machine-readable JSON into the worktree
- 03Spawn agent — Launch a Claude session scoped to that worktree directory
- 04Monitor — Wait for completion with a configurable timeout
The factory runs all specs in parallel using a ThreadPoolExecutor. With max_parallel_workers set to 8, eight agents work simultaneously, each in its own worktree, each on its own branch. The system prompt tells every agent: you're in an isolated worktree, your changes affect nothing else, follow the spec exactly, commit early and often.
Each agent operates in complete isolation. It can't see other worktrees. It can't modify files outside its worktree. The filesystem enforces the isolation that prompts alone can't guarantee.
Cleanup matters at scale. 194 worktrees consume real disk space, and abandoned worktrees accumulate stale lock files. The pipeline prunes worktrees after merge and runs git worktree prune to clean up stale references.
Here's the start of an actual 194-task run from the Awesome List project. The log captures worktree IDs, branch names, and launch timestamps as the factory spins up eight parallel workers:
Eight agents running simultaneously within six seconds. Each gets its own worktree, its own branch, and a declared file scope the orchestrator enforces. Durations vary wildly — 4m33s for a README change, 12m35s for a category that needed QA remediation before it earned approval. wt-003 failed its first attempt on agent timeout and the factory respawned it against a fresh session ID. wt-004 hit a QA rejection (missing error handling), got the specific remediation fed back to the same agent, and passed on the second pass. The queue (83 remaining at start) drains as workers complete and the next spec gets handed off.
Stage 4: QA Pipeline — Why Self-Review Doesn't Work
I learned this the hard way: QA agents must be separate from execution agents. The same biases that lead an agent to write buggy code lead it to overlook those bugs in review. A fresh agent with no memory of the implementation decisions catches things the builder agent rationalizes away. Ever reviewed your own PR and found a bug you'd been staring at for an hour? Same problem, amplified.
The QA agent receives three pieces of context: the original spec with acceptance criteria, the git diff of all changes, and any completion notes the execution agent left behind. It produces one of three verdicts:
- 01Approved — All acceptance criteria met, code quality acceptable
- 02Rejected with fixes — Specific issues identified, remediation instructions provided
- 03Rejected permanently — Fundamental approach flawed, needs re-specification
When the QA agent rejects a task, it doesn't just say 'rejected.' It provides specific failed criteria, detailed issues, and step-by-step remediation instructions. Those instructions get fed back to the original execution agent (still alive in its worktree) as a fix prompt. The agent applies fixes, commits, and the QA agent reviews again.
The numbers: 22% first-pass rejection rate, but 95% second-pass approval. The QA pipeline catches real stuff. Missing error handling. Edge cases the spec mentioned but the agent skipped. Hardcoded values that should be configurable. And because the fix cycle runs automatically, those 22% of tasks get repaired without any human touching them.
Stage 5: Priority-Weighted Merge Queue
194 worktrees produce up to 194 branches that all need to merge back to main. Naive sequential merging (branch 1, then 2, then 3) invites conflicts. Branch 150 will conflict with something branch 12 changed, and by that point nobody remembers why branch 12 made that change.
The merge queue uses a topological sort with priority weighting.
Here's how the merge algorithm works:
- 01Foundation tasks first — Shared infrastructure, type definitions, config schemas. No dependencies, merge cleanly by definition.
- 02Dry-run conflict check — Before every merge, git merge --no-commit --no-ff detects conflicts without applying changes. If conflicts exist, the merge gets aborted and the task gets flagged for re-execution against updated main.
- 03Small before large — Focused single-file tasks merge before broad refactors. Within the same priority, the sort is deterministic (alphabetical by task ID) so the merge order stays reproducible.
- 04Dependency ordering — A topological sort ensures no task merges before its dependencies.
The dry-run conflict check is cheap insurance. It takes milliseconds and prevents the only failure mode that would need human intervention: an unresolvable merge conflict in the middle of an automated pipeline.
When conflicts pop up, the task doesn't just fail. It re-enters the execution pipeline with an updated main branch as its base. The agent re-executes against the current state of the codebase, producing changes that account for everything that merged before it. More expensive than a clean merge, sure. But way cheaper than a human trying to resolve a three-way diff between two agents' competing visions.
The Ripple Rebase Problem
Session 0ea2a1c3 pushed this system to its limit. 21 active worktrees running simultaneously. The pipeline orchestrating creation, development, QA, and merge of 9 pull requests in sequence, PRs #8 through #16. Each PR built on the foundation laid by the previous one.
Here's the 'ripple rebase' problem that came up. After merging PR #8, every branch based on the pre-merge state of main needed to rebase. With 20 active branches, that's 20 rebase operations after each merge. Over the course of 9 merges, the system performed roughly 180 rebase operations.
Any one of those 180 rebases could've surfaced a conflict that didn't exist when the branch was first created. But they didn't. Every single rebase applied cleanly.
Why? File scope got declared up front. Branch A owns src/auth/. Branch B owns src/cache/. When A merges and B rebases, there are no conflicts because B never touched auth files. The scope boundaries guarantee non-overlapping changes, which guarantees clean rebases. Without scope declarations, those 180 rebase operations would've been a minefield. With them, every one was a no-op in terms of conflict resolution.
We also discovered a gh pr merge bug during this session, an edge case in GitHub's CLI that surfaces during rapid sequential merges. The specifics matter less than the meta-lesson: you only discover tooling bugs at scale. Nobody runs gh pr merge 9 times in rapid succession during normal development. The worktree factory made it routine.
When Worktrees Are the Wrong Answer
I want to be honest about the limits here. Worktrees add real overhead: disk space (each is a full working copy minus shared objects), cognitive load (tracking dozens of parallel streams), and merge complexity. For small changes touching fewer than three files, a single branch is simpler and faster.
For tightly coupled changes (shared state, database migrations, API contract changes) worktrees create the illusion of independence. Two agents can each build working code in isolation, but the code fails when combined because they made incompatible assumptions about a database schema. File scope checks catch file-level conflicts, but they can't catch semantic conflicts. I still don't have a great answer for that. If you've solved it, I'd genuinely love to hear how.
My rule of thumb: if two tasks share more than two files, they should be one task in one worktree. If a task requires understanding the output of another task to succeed, sequence them with a dependency. Don't parallelize.
The pattern works best when the codebase has natural boundaries. The Awesome List project had clear domain separation, with each list category as an independent module. The ILS iOS project had 35 worktrees distributed across isolated domains: macOS app, iCloud sync, multi-agent teams, custom themes, SSH service, performance optimization. The SSH service never touched iCloud sync files. Themes never touched performance code. The boundaries were natural, not forced.
The Numbers in Context
Across 23,479 total sessions in my development workflow, 18,945 were agent-spawned. Every one of those needed filesystem isolation from others working on the same project. The team coordination tools tell the scale story: 128 TeamCreate calls, 1,720 SendMessage calls between agents, 2,182 tasks created and tracked.
The worktree pipeline consumed 3,066 of those sessions across the Awesome List project alone. One project, one pipeline run: 194 ideated tasks, 91 specs, 71 worktrees, 71 QA reports, and 90 git branches. All converging back to a single clean main branch.
Here's the counterintuitive part: the overhead of writing specs, declaring file scopes, and running the five-stage pipeline costs less than a single merge conflict in a 194-branch system. One unresolved conflict cascades through every subsequent merge. Prevention costs minutes. Resolution costs hours.
Running It Yourself
The auto-claude-worktrees repo packages the full pipeline as a CLI tool:
Configuration lives in .auto-claude.toml:
Start with 3 worktrees to understand the pattern. Watch the agents work in isolation, see the QA pipeline catch issues, observe the merge queue converge everything cleanly. Then scale to 8 workers, then 20. The system scales linearly because the isolation guarantees hold at any count.
What Actually Changed
Before worktrees, I thought about agents as collaborators that needed to communicate and coordinate. Wrong framing. Now I think about them as isolated processes that need precisely defined interfaces. The worktree isn't a convenience feature. It's the unit of autonomous agent work. Each worktree gets its own spec, its own agent, its own QA reviewer, its own merge path. Everything you need is in this directory, everything you produce stays in this directory, and nothing outside this directory is your concern. That's the contract.
When Ralph (the orchestrator I describe in Post 8) runs across multiple worktrees, each one gets its own execution loop, its own cycle of implementation, verification, and correction. Ten named worktrees, each running independent loops, all producing commits on their own branches, all merging back through the same priority-weighted queue. The isolation makes it work. Without it, ten parallel agents produce chaos. With it, they produce a codebase.
The file scope declaration in the spec is the key insight. Not 'try not to conflict.' Not 'communicate if you need to touch shared files.' Declare your scope up front, and the system rejects you if your scope overlaps with any running agent. Prevention, not resolution. Rejection at task creation, not firefighting at merge time.
363 total worktrees across four projects. Peak of 35 simultaneous worktrees active at once. 9 PRs created and merged in a single session. A 47-task spec managing 21 active worktrees across phases. Zero merge conflicts.
Not because I got lucky. Because conflicts were structurally impossible.
Continue the series
- 05ValidationiOS Patterns from 4,597 Agent SessionsWhat 4,597 sessions taught me about SwiftUI, state, and survival — five patterns from three iOS apps that earned their keep or crashed.
- 07ValidationThe 7-Layer Prompt Engineering StackHow layered enforcement turned written rules into mechanical discipline across 23,479 AI coding sessions
- 08ValidationRalph: The Self-Correcting Hat-Based LoopOne hat per session, one event per hat, and the 1:47 AM guidance command that finished 28 tasks by morning
- 09ValidationMining 23,479 Sessions: What 3.4 Million Lines of AI Logs Actually RevealBuilding a pipeline to extract patterns from 11.6GB of Claude Code session data — and discovering the series was using the wrong numbers