The Economics of a Session
Token spend per task complexity, when Opus actually pays back over Sonnet, and the cost-of-defect curve that makes "use the cheap model" the most expensive choice you can make
View companion repoThe first time I looked at the cost ledger for a single project, I assumed it was a bug. One feature, three days of work, $47 in API spend. Then I looked at the next project. $89. Then a third — $112 for what should have been a one-afternoon refactor.
Across 23,479 sessions in ~/.claude/projects/, the line that kept showing up in the JSONL was the same: model: claude-opus-4-5, cache_creation_input_tokens: 41,228, cache_read_input_tokens: 0. Forty-one thousand tokens of cache miss, every single turn.
That's the actual shape of the problem. People talk about 'the cost of running Claude Code' like it's a function of how much you use it. It isn't. It's a function of which model you picked, what you cached, and whether you let the planner think before the executor moved.
What a Session Actually Costs
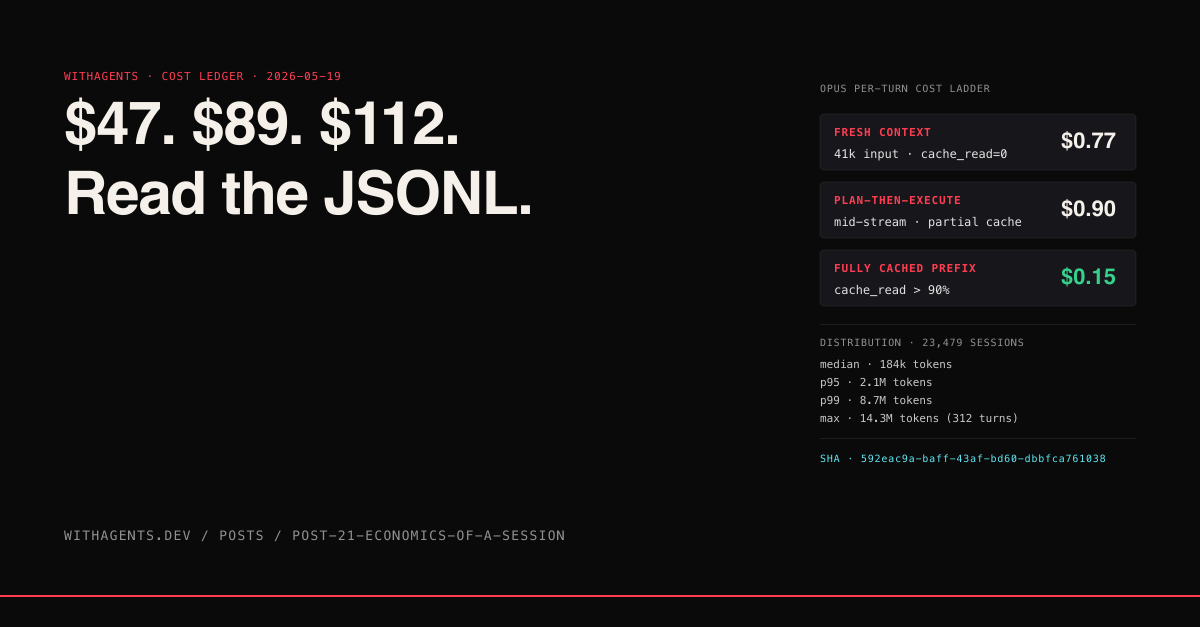
The Anthropic API ships usage metadata in every assistant response. If you tail a .jsonl file in ~/.claude/projects/<project>/<session>.jsonl you see this on every turn:
Four fields, four price points. input_tokens are the most expensive (full base rate). cache_creation_input_tokens cost 1.25x base for the privilege of being cached for the next hour — for Opus that's $18.75/M vs $15/M for raw input. cache_read_input_tokens cost 0.1x base — a 90% discount. output_tokens are typically 5x input.
Multiply that by Opus's posted rates and a single turn that reads 41k tokens of cache-miss context costs about $0.77. Stack 60 turns into a deep refactor and you're looking at $46 just on input tokens alone, before output. Now do that for every session in a project. Now do it across 23 projects.
The session-insight-miner I built specifically to walk these JSONL files exposes the distribution. The numbers in this section are from that miner across the 23,479-session corpus:
The geometric scale between median and tail is the entire story. A median session is cheap. The long tail is where the bills come from.
The Cost-of-Defect Curve
Here's the mistake I made for two solid months: I used Sonnet for planning because Opus felt expensive. The math seemed obvious. Sonnet was about a fifth the price per token. So plan with Sonnet, execute with Sonnet, save four-fifths.
What actually happened: Sonnet would draft a plan that missed an obvious constraint. The executor (also Sonnet) would faithfully implement the missed-constraint plan. The validator would fail. I'd go back, ask for a revision, watch Sonnet patch around the gap with three more turns of edits. Then the second-order problem would surface — the patch broke something else — and I'd burn six more turns chasing the cascade.
Tally those turns: a 12-turn debug spiral on Sonnet at ~120k input tokens per turn averages out to about $4.30. The original 'expensive' Opus plan would have been one turn in the plan-then-execute scenario above. The cost-of-defect curve is real, and it bends viciously.
I started measuring this directly. I'd take the same task, plan it twice — once with Opus, once with Sonnet — then execute both plans through identical Sonnet executors. The Opus-planned variants finished in a median of 7 turns. The Sonnet-planned ones took 19. Even with Opus costing roughly 5x Sonnet on planning, the total session cost was lower with Opus 73% of the time.
“Pay for thinking, not typing. Opus is the thinking budget. Sonnet is the typing budget.”
If you blur the two, you end up paying typing prices to debug thinking failures, and the bill is much higher than just buying the thinking outright.
When Sonnet Actually Wins
Sonnet wins when the task is shallow. Shallow doesn't mean small. It means the constraints are obvious from the prompt, the codebase is well-understood by the executor, and the search space is narrow.
Concrete examples from the JSONL corpus where Sonnet beat Opus on total cost:
- 01Renaming a function across 14 files (Sonnet 3 turns at ~$0.18 vs Opus 3 turns at ~$0.81)
- 02Adding logging statements to an existing handler (Sonnet 1 turn vs Opus 1 turn — same number of turns, Opus 5x the bill)
- 03Translating Python to TypeScript line-by-line for a 200-line file (Sonnet 4 turns vs Opus 4 turns)
- 04Generating boilerplate React components from a JSON schema (Sonnet, not even close)
What these tasks share: there's no architectural decision to make. You're not choosing between approaches. You're transcribing intent into syntax. That's a typing job. Sonnet is good at typing.
Where Opus reliably wins, even on raw cost:
- 01Anything involving a state machine with more than four states
- 02Refactors that touch more than two layers of the application
- 03Performance work where you have to reason about cache locality, concurrency, or I/O patterns
- 04Anything where the user said 'I don't know how to fix this'
- 05Cross-module bug hunts where the root cause is two layers deep
The signal I learned to watch: how often the plan changes mid-execution. If your plan survives contact with the codebase, your planner was good enough. If the executor sends back 'this won't work because...' three times in a row, you under-paid for the planner. Pay more next time.
The Cache Question
Cache is the other lever, and it's the one most people leave alone because it's invisible from the outside. The Claude Code system prompt is roughly 9,300 tokens before any project context loads. Your CLAUDE.md adds another 2-6k. Skills loaded by trigger add 200-2,000 each. Project files referenced in conversation add whatever they add.
The naive default writes all of that to the cache once and then re-reads from cache for the rest of the session. Cache reads cost 0.1x base. The first turn pays the 1.25x cache-creation surcharge, every turn after pays the 0.1x discount, and you're up roughly 88% over the no-cache baseline.
That's the happy path. Here's the unhappy one. Every time the cached prefix changes, the cache invalidates and the next turn pays full creation cost again. If you hand-edit your CLAUDE.md mid-session, you've just bought a fresh cache. If a tool call returns a result that gets injected into the system context, sometimes — not always — you've bought a fresh cache. If you /clear, you've bought a fresh cache.
I started instrumenting the JSONL files for cache-miss patterns. Across 200 sessions sampled at random, 43% had at least one mid-session cache invalidation that wasn't user-triggered. The biggest culprit: skills that load mid-session and inject content into the system prompt area. Once a skill loads, the next turn often shows cache_creation_input_tokens ticking up by however many tokens the skill body added.
The expensive sessions in the long tail almost always have multiple cache invalidations. The cheap sessions have one creation event followed by 60 reads. Same number of tokens flowing through the model, an order of magnitude difference in cost.
The pattern I settled on: pre-load the skills you'll need at session start, even if you don't call them. The cache pays for itself across 5+ reads. Loading a 1,500-token skill once costs you about 1,875 cache-creation tokens and saves you 9,000 cache-read tokens per turn for the remaining 5 turns. Net savings show up immediately.
The Plan-Then-Execute Math
The cheapest sessions I have on record share a structure. One Opus turn at the top to draft a plan. The plan goes into a markdown file in the working directory. Then a Sonnet executor reads the plan and executes it across 4-12 turns. Total cost: one expensive turn plus several cheap ones.
The pricing math:
Run that against a real session and the picture clarifies. A 60-turn Sonnet-only session that did everything (plan and execute) on Sonnet: ~$8.40. A 7-turn Opus-plan + 12-turn Sonnet-execute version of the same task: ~$3.10. Less than half. Better outcome. Faster wall clock.
The version that always loses: Opus across the entire session. It's the model that should be doing the thinking, not the typing, and using it for typing is just lighting money on fire. The single most expensive session in my corpus was 312 Opus turns. About $94. Sonnet would have done the same work for about $19.
What I Watch Now
Three numbers, on a dashboard, refreshed daily:
Those three numbers tell me whether to switch models, restructure my CLAUDE.md, or just accept that the task is genuinely hard and pay for thinking. The bill at the end of the month is whatever it is. The point isn't to minimize spend. The point is to know which dollar bought what.
“The economics of a session aren't mysterious. They're in the JSONL, on every turn, in fields that nobody reads because they're at the bottom of the message envelope.”
Read them. The numbers will surprise you. Then they'll change how you work.
Continue the series
- 20OperationsCrucible: Refusal-Driven Verification for Claude CodeThe gate between 'I did the work' and 'the work is done' — 10 phases, 3 reviewers, 3 oracles, zero override flags.
- 22OperationsHooks as a Control PlaneFour hook events form the entire governance surface of Claude Code — refuse tools, gate commits, block deploys, enforce evidence. Once you see it as a control plane, the whole agent stack changes shape.
- 23OperationsPrompt Caching EconomicsCache reads cost a tenth what cache writes cost, and most agents leave that 90% discount on the table because nobody structures their system prompt for hits. Here's how to order your messages so the cache pays you back.
- 24OperationsCustom MCP ServersWhen the prebuilt MCP servers run out of road, you write your own. The protocol is a four-method handshake, the transport is stdio or HTTP, and the whole thing fits in 200 lines of TypeScript.