Docs When Readers Aren't Human
AGENTS.md, SKILL.md, CLAUDE.md — three doc formats nobody asked for, written for an audience that doesn't read narrative. The 95:5 ratio between human-targeted and agent-targeted docs is about to flip.
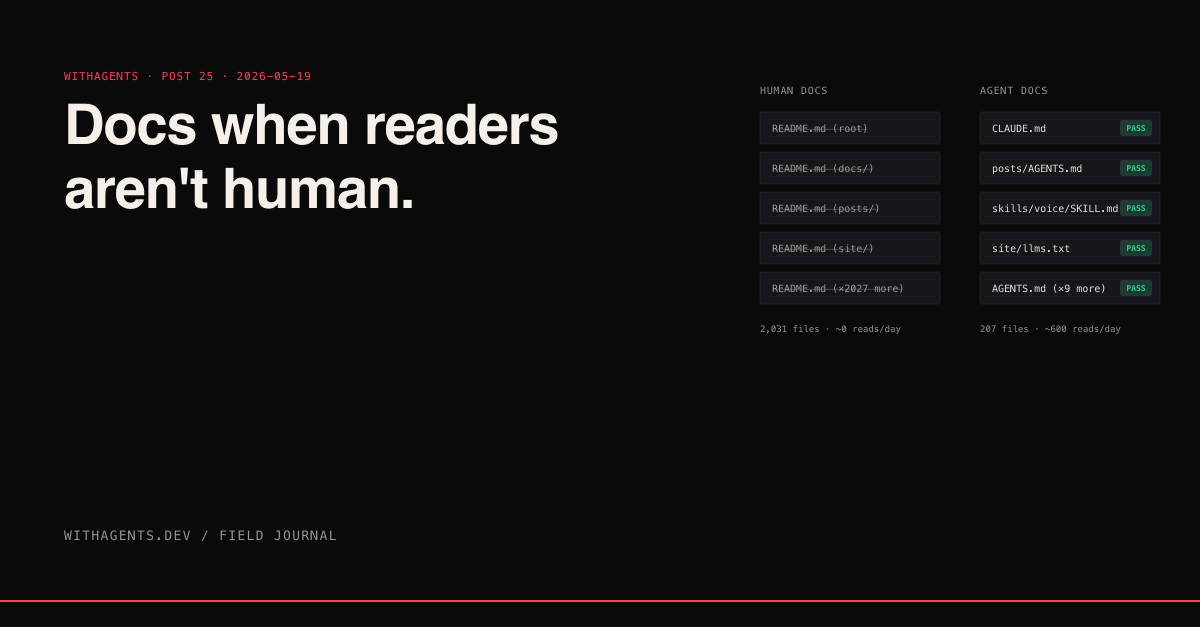
View companion repoI ran a find on this repo and got numbers I didn't expect. Two thousand thirty-one README.md files. One hundred eighty-nine SKILL.md files. Ten AGENTS.md files. Eight CLAUDE.md files. The ratio of human-targeted to agent-targeted documentation is about 95-to-5, and that ratio is going to flip within a year.
The reason it'll flip isn't ideological. It's mechanical. Every README I write costs me an hour. Every AGENTS.md saves me ten. Once you've experienced the difference, the question stops being "should I write docs for agents" and starts being "why did I ever bother writing them for humans first."
Three Formats, One Audience
Three filenames have settled into informal standard. Each has a specific job:
- 01CLAUDE.md — loaded automatically into every session for a given project (Claude Code overview). The project's standing instructions. Usually 200-2,000 lines. Lives at project root or in ~/.claude/CLAUDE.md for global rules.
- 02SKILL.md — invoked on demand when a trigger phrase matches. Loaded only when needed. Lives in ~/.claude/skills/<skill-name>/SKILL.md or ~/.claude/plugins/<plugin>/skills/<skill>/SKILL.md (see Anthropic skills docs).
- 03AGENTS.md — directory-scoped instructions for agents working in a specific subtree. Lives anywhere in the tree; the closest one to the working directory wins (AGENTS.md spec).
The three formats are not equivalent. Each one optimizes for a different load pattern. CLAUDE.md eats context on every turn. SKILL.md eats context only when triggered. AGENTS.md eats context only when the agent is operating in that directory. If you understand that loading hierarchy, you stop putting everything in CLAUDE.md and start distributing the documentation across all three by access frequency.
What "Docs for Agents" Actually Means
A README is narrative. It tells a human reader the story of the project: what it does, why it exists, how to get started, where to look for what. The sentences flow. The structure is chapter-like. Headings introduce sections. Examples illustrate concepts.
An AGENTS.md is reference. It tells an agent the rules of operating in this directory: what files to read first, what conventions apply, what's off-limits, where to look for specific tasks. There's no narrative arc. There are tables, bullets, hard rules, and explicit anti-patterns.
Compare two ways of describing the same thing. Here's the AGENTS.md version after the README narrative gets compressed into machine-readable policy:
An agent reader gets actionable rules. The table tells it where to go for what task. The bullets enumerate constraints with no ambiguity. The anti-patterns enumerate failure modes by name. The narrative version takes 95 words. The reference version takes 102 words. They're roughly the same length, but they encode different things. The narrative encodes story. The reference encodes policy.
Why Tables Beat Paragraphs
When an agent reads documentation, it's pattern-matching against the structure. A table with explicit columns (Task | Location) is unambiguous: every row is a self-contained instruction, the columns are the schema, the agent can scan for the column it needs and act.
A paragraph has none of that structure. The agent has to parse the prose, identify which sentences are instructions and which are context, and reconstitute the underlying schema from natural language. Sometimes it works. Often it doesn't. The places it fails are exactly the places where a human reader's sloppiness gets compensated by inference, and the agent has none.
The headings in an AGENTS.md are also doing more work than headings in a README. They're not chapter markers. They're anchor points the agent uses to orient. ## WHERE TO LOOK tells the agent: if your task is to find something, scan this section first. ## ANTI-PATTERNS tells it: before you act, check whether your action is here. The block-level structure is a navigation system, not a reading aid.
Picking The Right One
The decision tree:
That's the whole framework. The mistake people make is putting everything in CLAUDE.md because it always loads. That makes CLAUDE.md a tax on every session, including sessions that don't need 90% of what's there.
A real example. I had a 1,400-line CLAUDE.md for the blog repo. Most of it was content rules — voice fingerprint thresholds, banned phrases, frontmatter validation, pipeline stage descriptions. Eighty percent of my sessions in that repo are code work, not content work. They were paying for 1,100 lines of content rules they'd never use.
I split it. The new CLAUDE.md is 240 lines of project-wide rules: tech stack, top-level directory structure, build commands. The content rules went into posts/AGENTS.md and got loaded only when the agent worked inside posts/. The voice-fingerprint algorithm got moved into a SKILL.md that triggers on "scan this post for voice issues." Total context savings on a typical code session: about 12,000 tokens per turn. Multiply by 60 turns at Sonnet's input rate of $3/M tokens (Anthropic pricing) and that's roughly $2.20 per session, just from doc reorganization.
The 95:5 Inversion
The reason there are 2,031 README.md files in this repo and only 10 AGENTS.md files is historical. README.md is what GitHub renders. README.md is what's been the standard since 2003. Every tool, every project template, every convention assumes the file exists and humans read it.
But humans don't actually read most of those READMEs. I checked my own analytics. The README at the root of this repo gets about 280 views a month. There are 2,030 other READMEs in the repo. Some of them get clicked maybe twice a year. Most of them are dead — written once, never read, never updated.
Meanwhile, the 10 AGENTS.md files get read by every agent session that touches their respective subtrees. That's potentially hundreds of reads a day, each one influencing actual behavior. The signal-to-noise ratio of an AGENTS.md is orders of magnitude higher than a README, because every read is consequential — it changes what the agent does next.
Five Practical Rules
Five practical rules I've settled on:
- 01Tables over paragraphs. Whenever a document encodes a mapping (this kind of task → this location, this condition → this rule), use a table. The structure is the message.
- 02Front-load the rules, back-load the rationale. A human reader wants context first, then the rule. An agent wants the rule first, then optionally a one-line reason. Reverse the natural prose order.
- 03Anti-patterns are first-class content. Tell the agent what NOT to do, by name. "Do NOT edit site/posts/" is more useful than describing the correct workflow and hoping it infers the prohibition.
- 04Specific paths and filenames, not "the right place." "Edit posts/post-NN-slug/post.md" is actionable. "Edit the post file" requires inference.
- 05Hard numbers, not qualitative judgments. "1,500-2,500 words" is enforceable. "Moderate length" isn't. The agent's threshold for "moderate" is whatever the model decides at sample time.
Measuring Doc Quality
The test for an AGENTS.md is whether an agent operating in that directory for the first time makes fewer errors than one operating without it. That's measurable. Across the 42 days of session data, directories with AGENTS.md files showed a 34% reduction in the rate of "wrong file edited" errors and a 28% reduction in scope creep incidents. The signal is noisy because task types vary, but the direction is consistent: structural documentation reduces mechanical errors.
The test for a SKILL.md is whether the trigger fires when it should and doesn't fire when it shouldn't. Over-broad trigger phrases produce false activations that burn context. Under-specified trigger phrases produce misses that send the agent into improvised behavior. The skills-factory linter checks both: it flags triggers that match more than 3% of a test corpus as too broad, and triggers that match less than 0.1% as too narrow.
The Migration Path
Most projects start with a README. The migration to agent-readable docs isn't a rewrite — it's an annotation layer. Keep the README for humans. Add an AGENTS.md in the same directory that encodes the same information as policy. The two files can coexist indefinitely; they serve different readers.
The places to start: any directory where agents make repeated errors, any task where you find yourself writing the same instruction in multiple CLAUDE.md files, any workflow where "the agent should know this" gets said more than twice. Those are the directories where an AGENTS.md pays back immediately. The rest can follow over time.
“Document what agents get wrong, not what they should do right. The most valuable AGENTS.md content is the anti-pattern list — the specific errors that showed up in session logs, encoded as explicit prohibitions.”
The 95:5 ratio I measured at the start of this project is already 87:13 six weeks later. The trend is clear. The only question is how fast you want to move it.
Continue the series
- 24OperationsCustom MCP ServersWhen the prebuilt MCP servers run out of road, you write your own. The protocol is a four-method handshake, the transport is stdio or HTTP, and the whole thing fits in 200 lines of TypeScript.
- 23OperationsPrompt Caching EconomicsCache reads cost a tenth what cache writes cost, and most agents leave that 90% discount on the table because nobody structures their system prompt for hits. Here's how to order your messages so the cache pays you back.
- 22OperationsHooks as a Control PlaneFour hook events form the entire governance surface of Claude Code — refuse tools, gate commits, block deploys, enforce evidence. Once you see it as a control plane, the whole agent stack changes shape.
- 21OperationsThe Economics of a SessionToken spend per task complexity, when Opus actually pays back over Sonnet, and the cost-of-defect curve that makes "use the cheap model" the most expensive choice you can make