84 Thinking Steps to Find a One-Line Bug
How structured hypothesis-test-revise chains solve bugs that brute force debugging never will
View companion repoTwo days. Four engineers. Nobody found the bug.
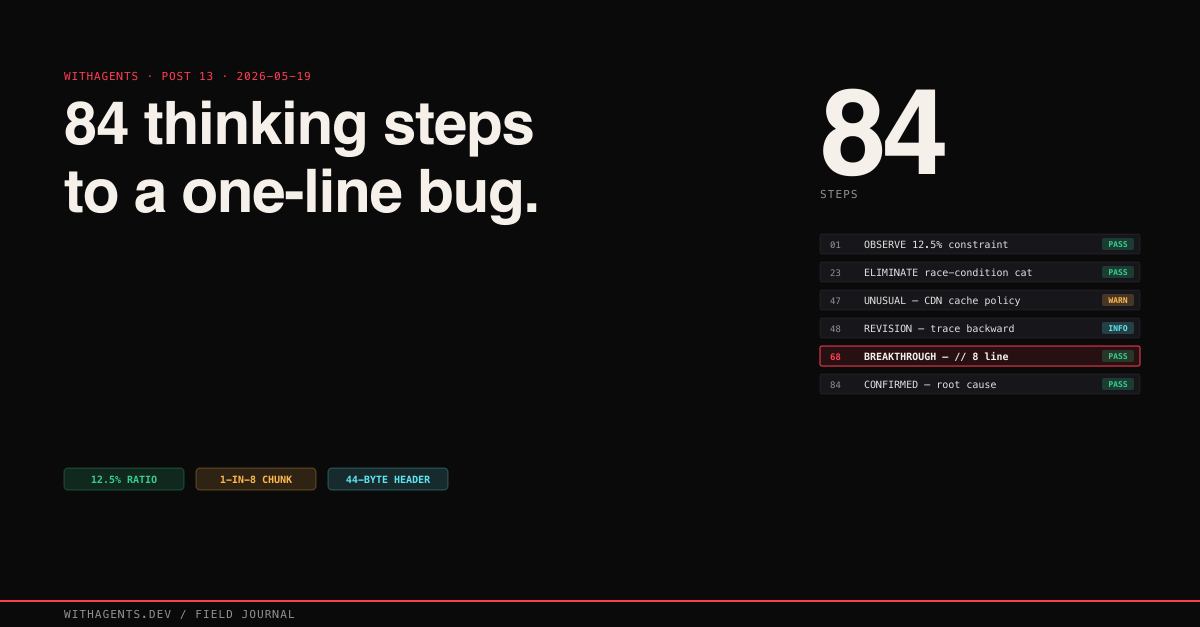
Then an 84-step sequential thinking chain traced it through four system layers to a single integer division that skipped a 44-byte WAV header. One line. That’s it.
That chain changed how I debug everything. Not because the tool is magic. It works because it forces a discipline human debugging resists: you can’t skip from “this looks weird” to “this must be the bug” without writing down exactly why.
Why Brute Force Debugging Fails
You see a symptom. You form a hunch. You jump to the code that “feels” responsible. Print statements. Change something. Re-run. When the hunch is right (about 40% of the time) this works fast. When it’s wrong, you spiral. Two hours later you’re debugging your debugging.
Across 23,479 sessions over 42 days, the hardest bugs were never in a single component. They live in the gaps between layers, between what one service sends and what another expects. Debugging one component at a time can’t find these bugs because no component is broken in isolation.
Sequential thinking, Claude Code’s MCP tool for structured reasoning chains, forces a different approach. Each step is numbered. Each step builds on the previous ones. Each step states what it’s checking, what it predicts, what it concludes. You can branch. You can revise. You can’t skip. That constraint is what makes it work on bugs that resist brute force.
Across 23,479 sessions, I recorded 327 sequentialthinking invocations. That number is deceptively small. Each invocation is a multi-step chain, not a single thought. The 84-step WAV chain was one invocation that ran for over an hour. You reach for this when the standard playbook has failed.
The Bug Nobody Could Find
The symptom: audio corruption affecting exactly 1 in 8 playbacks. Not “sometimes.” Exactly 12.5%. That precision became the anchor constraint that cracked the case.
The audio pipeline served WAV files through a CDN with byte-range support. Users reported garbled audio on roughly every eighth play. The standard playbook ate two days: four engineers checked the audio encoder, CDN config, React player, PostgreSQL metadata store. Everyone found something suspicious. Nobody found the bug.
I fed the problem to the sequential thinking tool. Constraint first: “The failure rate is exactly 12.5%, which is 1/8. The root cause must produce exactly this ratio.”
Inside the Chain: A Representative Trace
Each step is a sentence or two. Here’s a representative trace, reconstructed from the chain structure and bug details, showing the shape of the reasoning, not a verbatim log.
That’s 15 steps out of 84. The structure is the same throughout: state what you’re checking, predict, test against the constraint, eliminate or revise. Steps 1-22 feel like stalling. But establishing the constraint precisely is what makes step 20 instant: you evaluate the entire category against the constraint and eliminate them all at once.
Steps 1-22: Establishing the Constraint
The first 22 steps established what the bug could and couldn’t be. 12.5% is 1/8. What creates an 8-state cycle here? The CDN uses 8 edge servers. Audio chunking divides files into 8 segments. The database connection pool has 8 connections. Three sources of “8,” three different root causes.
Most debugging would’ve jumped straight to the CDN. Eight servers, one’s misconfigured, case closed. Sequential thinking demanded more: if one CDN server is misconfigured, failure rate depends on load balancing. A round-robin load balancer produces approximately 12.5%, not exactly 12.5%. “Exactly” eliminates “approximately.”
Steps 23-46: Category Elimination
Step 23 was the first breakthrough. The leading theory: a race condition in the CDN cache, two concurrent requests occasionally corrupting cached audio. Sequential thinking rejected it. Race conditions produce variable failure rates that depend on load. A fixed 1/8 ratio means a fixed cause.
Constraint-based debugging eliminates categories, not individual hypotheses. Step 23 didn’t kill one race condition theory. It killed all race condition theories at once. One step, dozens of causes eliminated.
“Constraint-based debugging eliminates categories, not individual hypotheses.”
Steps 24-46 continued the pattern. Encoding bugs affect all plays, so the encoding category dies. Player-side bugs would show in the player’s debug output, which was clean. The client category dies. By step 46, the search space had collapsed to “something in the data path that produces exactly 8 states.”
Steps 47-67: The Trap of "Unusual"
Step 47 found something that looked like the answer. The CDN had an unusual byte-range caching policy. “Unusual” felt like “root cause.” Most engineers would’ve stopped here.
Sequential thinking pushed back. Step 48 was a revision: unusual isn’t root cause. The CDN response was correct given the offset it received. The right question wasn’t “why is the CDN doing something weird?” but “why is the CDN receiving a weird offset?”
Writing “REVISION of step 47: the CDN behavior is a symptom, not a cause” forces you to keep going when your gut says stop. Steps 49-67 traced backward through the API gateway to the PostgreSQL query that generated the byte-range offset.
Steps 68-84: The Root Cause
Step 68 found the actual line:
WAV files have a 44-byte header containing sample rate, bit depth, channel count, and data length. The offset calculation divided file size by 8 for byte-range chunks, but chunk 1 included the WAV header as audio data. The client got 44 bytes of header metadata decoded as audio samples. Garbled. With 8 chunks, exactly 1 in 8 requests hit chunk 1. Exactly 12.5%.
The fix:
“One line. The fix took seconds. Finding the problem took 84 steps across four architectural layers. Almost all the work was in finding it.”
The Hypothesis-Test-Revise Cycle
The 84-step chain followed a repeating pattern I’ve since turned into a methodology. Three phases:
Hypothesize: State what you think is happening. A specific, testable claim. “The CDN is misconfigured” isn’t a hypothesis. “One of 8 CDN nodes returns incorrect Content-Range headers, causing 12.5% of requests to receive garbled audio.” That’s a hypothesis. Specific enough to test, specific enough to eliminate.
Test: Make a prediction that would be true if the hypothesis holds. “The CDN logs will show one node returning different headers” is testable. “Something is wrong with the CDN” is not.
Revise or Eliminate: If the prediction fails, state which constraint the hypothesis violates, then kill it. If it partially succeeds, revise and form a refined hypothesis. The WAV debugging had 3 hypotheses eliminated and 2 revisions before the root cause.
This cycle maps directly to the companion repo’s DebuggingChain API:
The DebuggingChain tracks every hypothesis, records every elimination with its reason, and generates a report showing how the search space narrowed. Same discipline as the MCP tool, codified into a reusable framework.
When Not to Think: The Stale Cache Problem
Not every bug needs 84 steps. Some need zero steps and a server restart.
A Next.js API route returns 404. File exists on disk. Export is correct. Path matches the convention. The agent’s 34-minute escalation chain:
- 01Checked the file path — correct
- 02Verified the export — default export, correct signature
- 03Renamed the file — still 404
- 04Moved the file to a different directory — still 404
- 05Added console.log to the handler — no output
- 06Deleted and recreated the file — still 404
- 07Searched Next.js docs for route resolution rules
- 08Restructured the entire directory
- 09Considered switching to Express
The fix: restart the dev server. Two seconds.
The route file was created while the dev server was running. Next.js had already built its route map. The new file existed on disk but not in the server’s in-memory route table. HMR didn’t pick up new route files in certain directory configurations.
Thirty-four minutes of sophisticated debugging. Two seconds of Ctrl+C and pnpm dev.
I built a PostToolUse hook to catch this automatically:
Five types of stale cache, ranked by how often they bite:
Before reaching for sequential thinking, run the 10-second checklist: restart the process, clear caches, verify runtime matches source. Those bugs aren’t hard. They’re invisible to reasoning. No amount of thinking about correct code will find a bug that doesn’t exist in the code.
The Constraint Propagation Principle
Start with a quantitative constraint. Use it to eliminate categories, not individual hypotheses.
“12.5%” eliminated all race conditions in a single step. Not “this specific race condition” but all race conditions, because none produce a deterministic ratio.
Quantitative constraints compose. Failure rate exactly 12.5%, AND system has 4 layers, AND failure only affects audio: you’ve eliminated most of the search space before writing a single line of debugging code. Each constraint multiplies the elimination power of the others.
This applies beyond audio bugs:
- 01“It fails every 3rd request” eliminates timing-based causes and points to round-robin or modular arithmetic.
- 02“It only fails for files larger than 2MB” eliminates logic bugs and points to buffer sizes or API limits.
Each constraint is a filter. Stack enough filters, and the root cause is the only thing left.
Building the Debugging Chain Framework
The companion repo at sequential-thinking-debugging codifies this methodology into a Python framework. The core abstraction is the DebuggingChain, a sequence of typed steps where each step declares what it is (observation, hypothesis, test, elimination, revision, or root cause confirmation) and what it references.
The framework enforces the discipline that makes sequential thinking effective. You can’t confirm a root cause without testing it. You can’t eliminate a hypothesis without citing which constraint it violates. You can’t revise a step without referencing the step you’re revising. Every shortcut human debugging takes gets structurally prevented.
Here’s the CLI:
The Debugging Decision Tree
Use sequential thinking when:
- 01The bug spans multiple system layers (root cause isn’t in the component showing the symptom)
- 02You have a quantitative constraint (specific frequency, timing, or threshold)
- 03Multiple engineers have already looked and found nothing
- 04Your first two hypotheses were both wrong
- 05The bug is intermittent but with a pattern
Use brute force when:
- 01The bug is in a single file or function
- 02The error message points directly to the cause
- 03A print statement would show the answer in seconds
Restart first when:
- 01You just changed a config file, route, or schema
- 02The behavior doesn’t match the code you’re reading
- 03“It was working a minute ago”
327 sequential thinking invocations across 23,479 sessions means I use it 1.4% of the time. That’s the right number. Sequential thinking is a precision instrument, not a daily driver. The other 98.6% of the time, the standard toolkit works. For that 1.4%, nothing else comes close.
What 84 Steps Actually Looks Like
People hear “84 steps” and imagine tedium. It’s the opposite. Each step is a sentence or two. The discipline isn’t length, it’s structure. You’re maintaining a chain where each link connects to the previous ones and every hypothesis gets tested against every constraint.
The WAV chain averaged 15 words per step. 84 steps at 15 words is roughly 1,260 words, less than this section. The time wasn’t spent writing. It was spent thinking. The steps forced that thinking to be explicit, traceable, revisable. When step 48 revised step 47, the revision was visible. In unstructured debugging, you’d quietly abandon a theory and lose the reasoning about why it was wrong. In a chain, the revision is recorded. It informs everything after.
I’m not 100% sure 84 steps was the sweet spot. Maybe 60 would’ve gotten there. Maybe the first 22 constraint-establishment steps could’ve been tighter. But the point isn’t optimizing step count. Every step left a trail, and that trail made the revision at step 48 possible. Without it, I’d have stopped at “unusual CDN config” and burned another day.
The four engineers who spent two days weren’t less skilled. They were less structured. Each had a piece of the answer. Nobody had assembled the chain that connected the unusual caching policy to the offset calculation to the 44-byte WAV header. That assembly is what the chain forced.
Sequential thinking found the bug because it forced all four layers into a single chain of reasoning. One chain, one debugger, one bug. The next post inverts that picture: when one chain isn’t enough and the work has to fan out across many agents in parallel, parallelism stops being an optimization and starts being a coordination problem of its own.
The sequential-thinking-debugging companion repo has the full framework: DebuggingChain with typed steps, hypothesis tracking, constraint propagation, and report generation. Clone it, feed it a bug with a quantitative constraint, and watch it eliminate hypothesis categories faster than you can type them. The WAV bug demo runs in a single command: seq-debug demo.
Continue the series
- 12Memory & HooksTeaching AI to Remember: Cross-Session MemoryA SQLite observation store and MCP memory server that turns 23,479 sessions of amnesia into searchable institutional knowledge
- 14Memory & Hooks35 Worktrees, 12 Agents, Zero Merge ConflictsParallelism gets agents working at the same time. Choreography is what keeps their work from eating itself alive when they finish.
- 11Memory & HooksSpec-Driven Development: Why YAML Beats Verbal Instructions for AI AgentsA single YAML file replaces meetings, tickets, and Slack threads — agents read it, build in parallel, and ship without asking clarifying questions
- 10Memory & HooksThe Designer-Less Design Workflow: Stitch MCP and the Death of Figma Handoffs269 AI-generated screens, zero Figma files, and the branding bug that taught me to treat prompts as build artifacts