Drift Detection
Specs and code diverge silently. The 60-day audit pattern, the four-class taxonomy (dead, drifted, lying, fine), and what I do every quarter to make sure my docs still describe what my code actually does.
View companion repoI keep dated planning directories. They look like plans/260305-content-pipeline-v2/, plans/260420-syndication-engine/, ten of them now spanning the past year. Each one has a PLAN.md, an ARCHITECTURE.md, sometimes a HANDOFF.md, and a list of decisions from the moment I made them.
About 60 days after each plan went live, I started noticing the same thing every time: the plan was lying. The code didn't match it. The architecture had drifted. The decisions documented in the handoff had been quietly reversed by some commit that didn't update the docs.
That's drift. It's the slow divergence between what your written intent says and what your code actually does, and it accumulates whether you notice or not (Kinde, *Spec Drift: The Hidden Problem*). I built an audit pattern for it because the alternative — assuming docs match code — kept biting me; published research finds documentation mismatches correlate with higher defect rates and schedule slips (IEEE, *A Review on Detecting and Managing Documentation Drift*).
The Four-Class Taxonomy
When I audit a spec against code, every claim in the spec falls into one of four buckets:
- 01DEAD — the spec describes something that no longer exists. The code referenced got deleted, the feature got removed, the file path is gone.
- 02DRIFTED — the spec describes something that exists but has changed materially. The function still has the same name; its behavior is different.
- 03LYING — the spec describes something that exists and never existed in that form. Aspirational text that someone wrote describing how things should work, but never did — a pattern over-requirement research attributes to the planning fallacy, where teams systematically commit to more features than they can ship under optimistic estimates (Academia.edu, *The Planning Fallacy as an Explanation for Over-Requirement*).
- 04FINE — the spec describes something that exists and matches reality.
The four classes are mutually exclusive and (in my experience) collectively exhaustive. Every paragraph in a spec maps to one of them. The audit pass walks through the spec, classifies each claim, and produces a report that's actionable. The hard part is the classifier. There's no automated way to tell DRIFTED from FINE without reading the code and the spec side by side — recent program-comprehension research treats Design-Implementation-Documentation (DID) drift detection as an open problem requiring human-in-the-loop traceability (ACM ICPC 2024). So the audit is necessarily human-driven, with tooling assistance.
The 60-Day Trigger
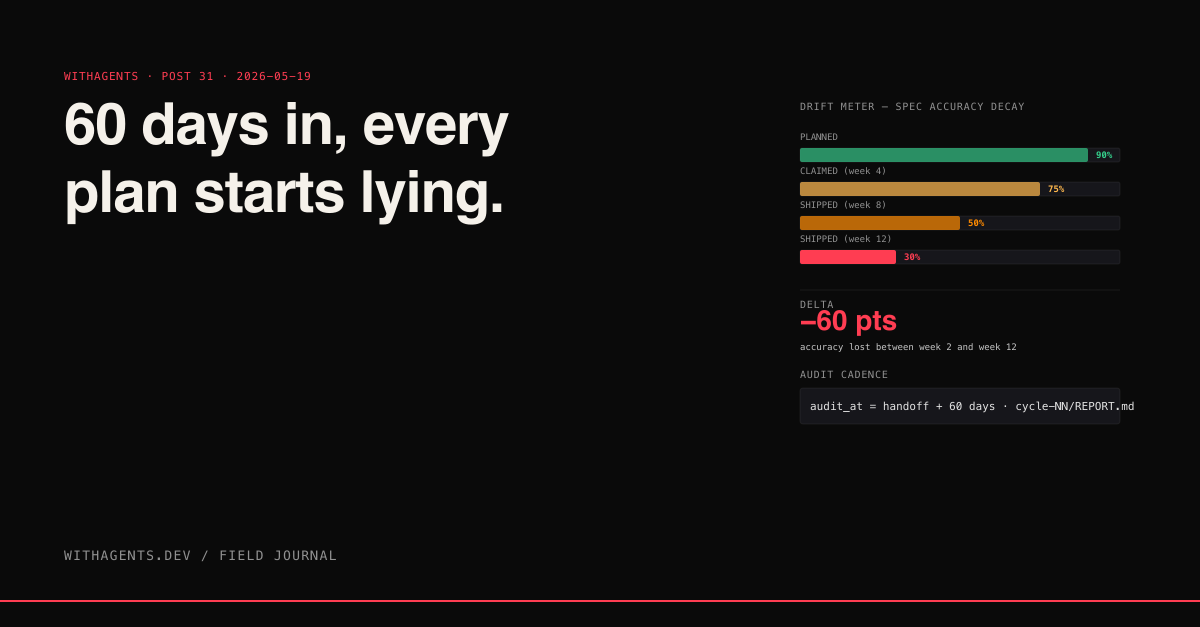
Why 60 days? Because that's roughly the half-life of accuracy in my project specs. Across the ten dated plan directories I audited, the average spec was 90% accurate at week two, 75% accurate at week four, 50% accurate at week eight. By twelve weeks it was 30% accurate — most of the document had been overtaken by code changes.
The decay isn't linear. There's a cliff somewhere between week six and week ten where major refactors happen, decisions get reversed, and the spec falls off a cliff. Audit before the cliff and you're maintaining minor drift. Audit after the cliff and you're rewriting the document.
So I audit at 60 days. Calendar-driven. Every plan directory gets a check-in two months after its handoff date, regardless of whether I think it needs one. The check-ins that find nothing wrong (rare) take 20 minutes. The ones that find significant drift (most) take 1-2 hours.
The Audit Procedure
Three passes. Each pass produces a different artifact.
Pass 1: Existence check
Walk every file path mentioned in the spec. For each one, run ls and check if it exists. For each function or class name mentioned, run rg to confirm it's still in the codebase. Anything that returns "not found" is provisionally DEAD.
Twenty lines. Catches the cheap cases. Anything flagged here is unambiguous — the thing the spec describes literally isn't in the codebase anymore.
Pass 2: Behavior check
For each behavior claim in the spec ("returns 200 on success," "validates the user_id field," "rate-limits at 60 per minute"), find the corresponding code and read it. Confirm the behavior matches the spec or flag the divergence.
This pass can't be automated. The classifier is human. The tooling helps by surfacing claim-code pairs efficiently — rg for the symbols mentioned in each claim, hyperlinks to the source files, side-by-side diff view. But the actual classification ("does this rate-limiter implementation actually rate-limit at 60/min?") requires reading the code and matching it against intent.
Pass 3: Decision check
Every decision documented in the handoff (HANDOFF.md or equivalent) gets verified. Was the decision actually implemented? Did a later commit reverse it without updating the doc? This is where LYING claims tend to surface — decisions written down that never actually shipped.
Eighteen lines. Coarse but useful — surfaces decisions that have no corresponding commit history, suggesting they were either never implemented or implemented under different naming.
The Output Format
The audit produces a markdown report. Header: Drift audit on plans/260305-content-pipeline-v2/, audit date 2026-05-04, days since plan 60.
Recommended actions: update Stage 3 description (DRIFTED #1), update output format documentation (DRIFTED #2), remove parallel-execution claim or implement it (LYING #1), remove Slack-notification claim or implement it (LYING #2), delete or archive references to deleted files (DEAD #1, #2, #3, #4).
The report is checked into the project as audit-evidence/cycle-NN/REPORT.md. The numbered cycles let me track audit history. The audit-evidence/ directory accumulates over time — a record of what drifted and when, useful for spotting which parts of the spec are most prone to lying.
What Gets Found
After three audit cycles across two projects, the patterns of drift cluster:
- 01Most common: Implementation detail drift (DRIFTED). A function that takes three arguments now takes four. A return type that was a string is now an object. About 60% of all drift findings.
- 02Second most common: Renamed but functionally equivalent (DRIFTED). A class called PipelineRunner got refactored to PipelineExecutor. Functionality identical; name changed. About 20% of findings.
- 03Third: Removed features (DEAD). Something that was in the spec at handoff time got cut from the implementation, but the spec never got updated. About 10% of findings.
- 04Fourth: Aspirational text that never shipped (LYING). The plan said something would happen, the work item didn't survive triage, the spec still says it. About 10% of findings.
DRIFTED findings are the cheapest to fix — most are one-line spec edits to update the new name or signature. DEAD findings are also cheap — delete the paragraph. LYING findings are the most embarrassing because they reveal aspirations that didn't get implemented; the right move is usually to either implement them now or admit they're not happening.
Why This Beats "Just Update Docs As You Go"
Every team I've worked with has the policy "update the docs as you change the code." Every team I've worked with also has docs that drift — practitioner write-ups consistently attribute this to tight deadlines, code-first development, and unclear documentation ownership (Docsie, *Documentation Drift*). The policy doesn't work because it depends on individual discipline applied consistently across every commit, which never actually happens.
The audit pattern works because it batches the discipline into a deliberate, scheduled activity. Once a quarter (or once per plan-cycle), you sit down with the spec and the code and reconcile them — quarterly is the broadly recommended cadence for control reviews because without a defined schedule, controls drift and reviews end up missing or backdated (Konfirmity, *SOC 2 Evidence Review Cadence*). The work is concentrated, the output is a clear delta, the cost is bounded.
The 60-day audit on the dated plan directories has saved me from shipping wrong information to my team three times in the past year. Each time, the spec still said something that the code had stopped doing months earlier. If a teammate had relied on the spec to make a decision, they would have been working from incorrect information. The audit caught it before that happened.
“Drift is inevitable. Audits are how you keep it from compounding. Sixty days is the threshold I've found works. The four-class taxonomy is what makes the output actionable. The whole pattern fits in a single afternoon every two months, and the alternative is shipping software whose docs lie about it.”
Continue the series
- 30Edge CasesNotification Architecture for Async AgentsAgents finish at three in the morning. Severity model, channel routing, the exhausted-state-fires-alert pattern. The notification layer that lets you sleep while your work runs.
- 32Edge CasesThe 529 CascadeAnthropic returns 529 (overload) intermittently. Naive retries themselves consume the bucket and storm the API a hundred times over. The retry policy that costs less, not more.
- 29Edge CasesThe Skill Marketplace ProblemSeventy-one marketplaces subscribed. One hundred thirty-two plugins installed. Twenty-six marketplaces installed-but-unused. The discovery overhead is the bottleneck — and it's getting worse.
- 33Edge CasesOrbit: Find Drift Between What You Asked and What Actually ShippedPlans are evidence, not history. Mining the JSONL session transcripts you already have on disk to compare intent against claim against codebase truth.